Oficinas em
Ciência de Dados
Modelos de Regressão, Agrupamento,
Redução de Dimensionalidade e Hands-on
Agenda do Dia
- Introdução à Modelagem Estatística (15min)
- Regressão Linear (25min)
- Regressão Logística (25min)
- Pausa (10min)
- Hands-on - Parte 1 (40min)
- Redução de dimensionalidade (15min)
- Agrupamento (15min)
- Pausa (10min)
- Hands-on - Parte 2 (40min)
O Que é Aprendizado de Máquina?
Aprendizado de Máquina (Machine Learning) é uma área da inteligência artificial que permite aos computadores aprender e tomar decisões a partir de dados, sem serem explicitamente programados para cada tarefa específica.
Diferença fundamental:
- Programação tradicional: Dados + Regras → Respostas
- Aprendizado de máquina: Dados + Respostas → Regras
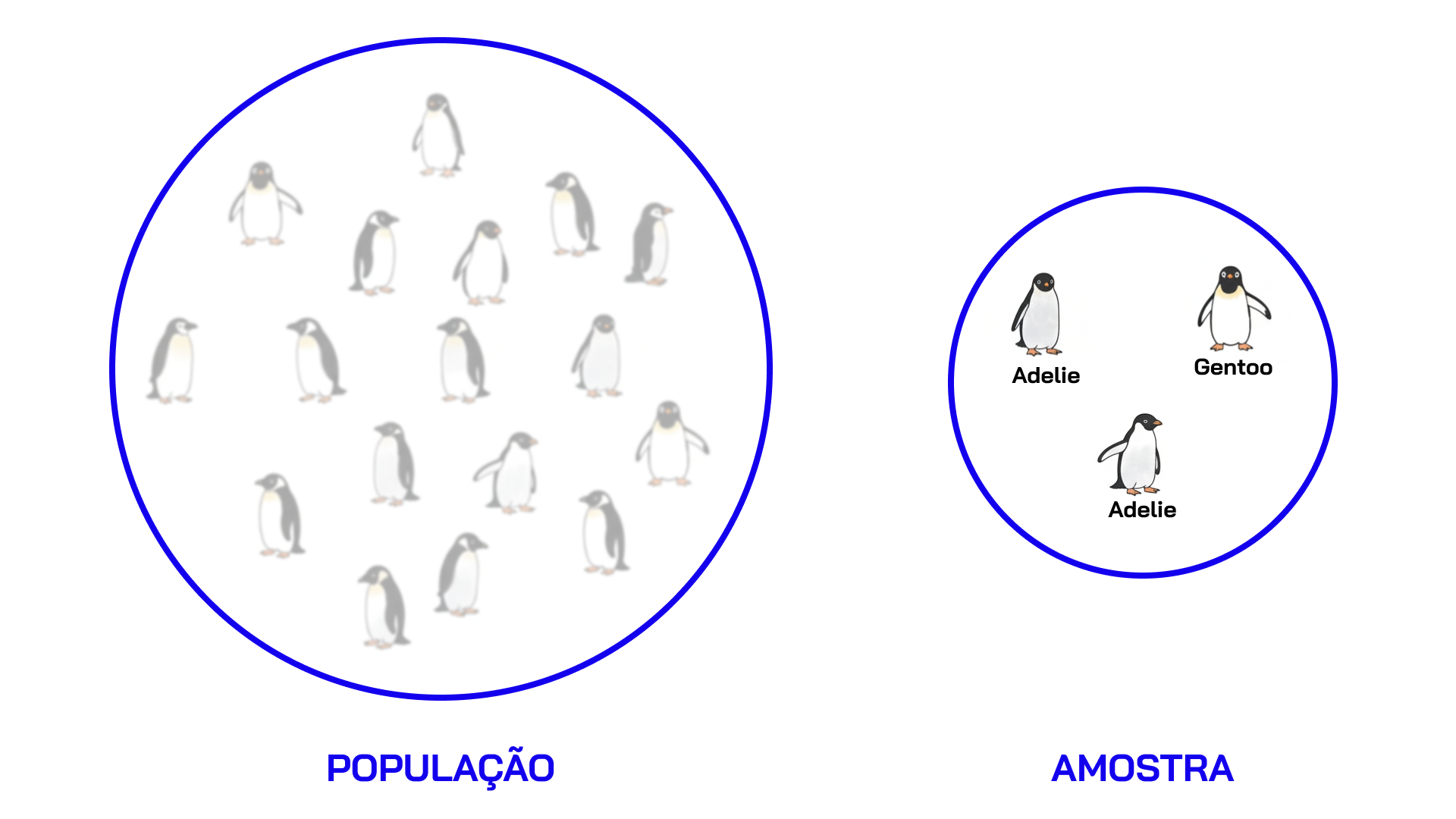
Aprendizado Supervisionado
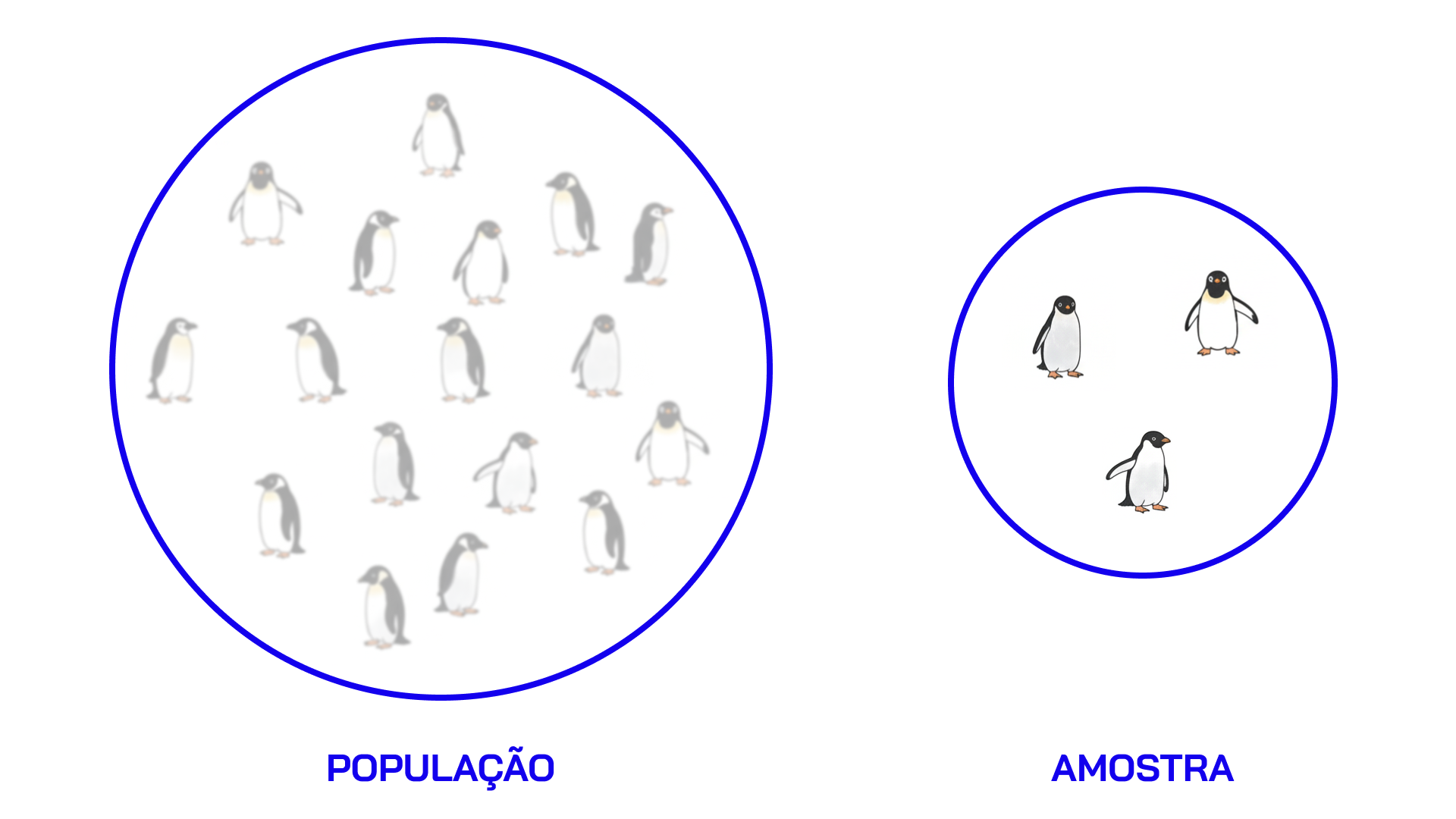
Aprendizado Não-supervisionado
Outros Tipos de Aprendizado
Semi-supervisionado: Combina dados rotulados e não-rotulados
Por reforço: Aprende através de tentativa e erro com sistema de recompensas
Self-supervisionado: Cria próprios rótulos a partir dos dados
Transfer Learning: Reutiliza conhecimento de tarefas similares
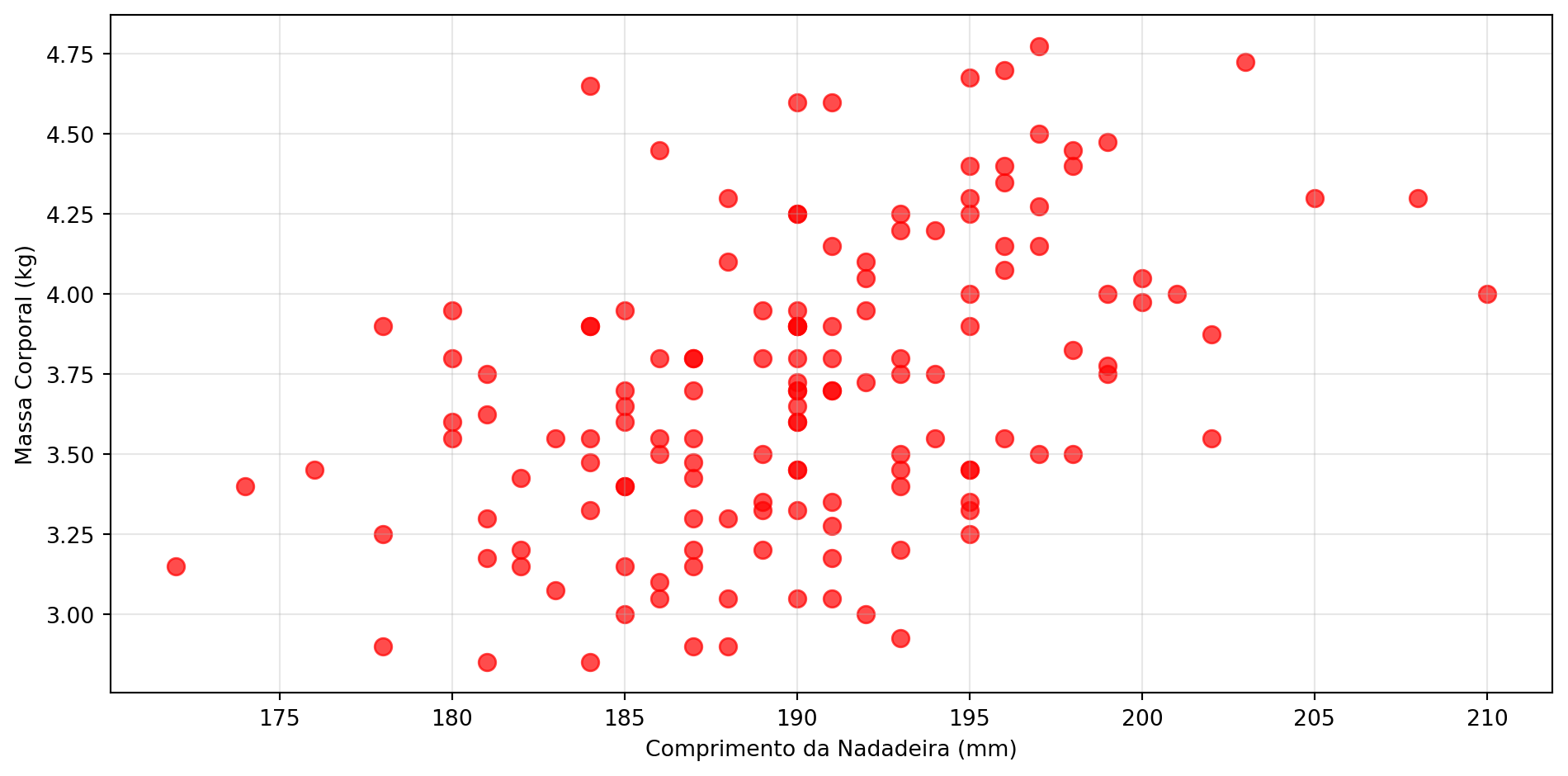
Tentando Descobrir um Padrão
Identificando uma Tendência
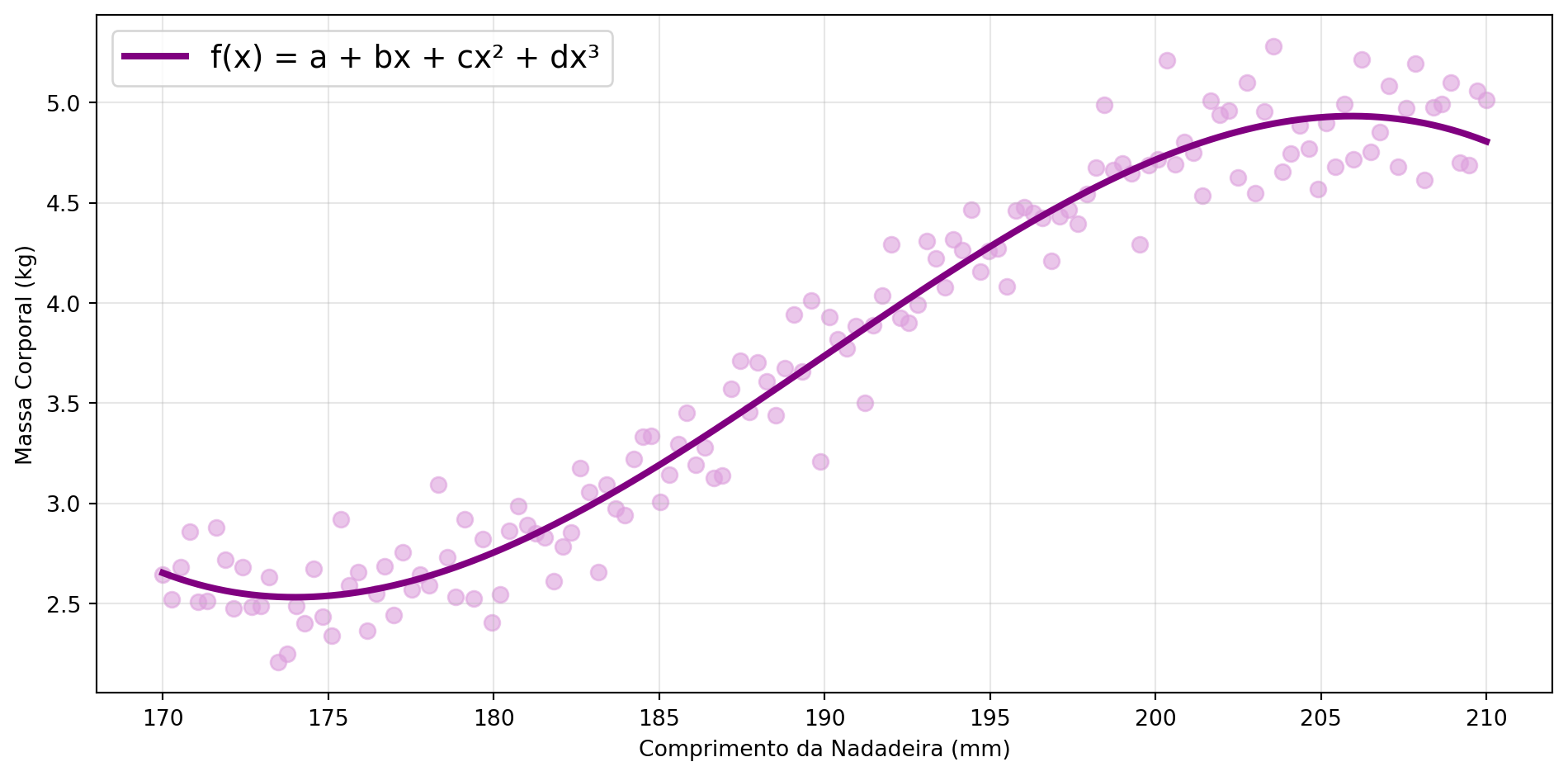
Infinitas Possibilidades
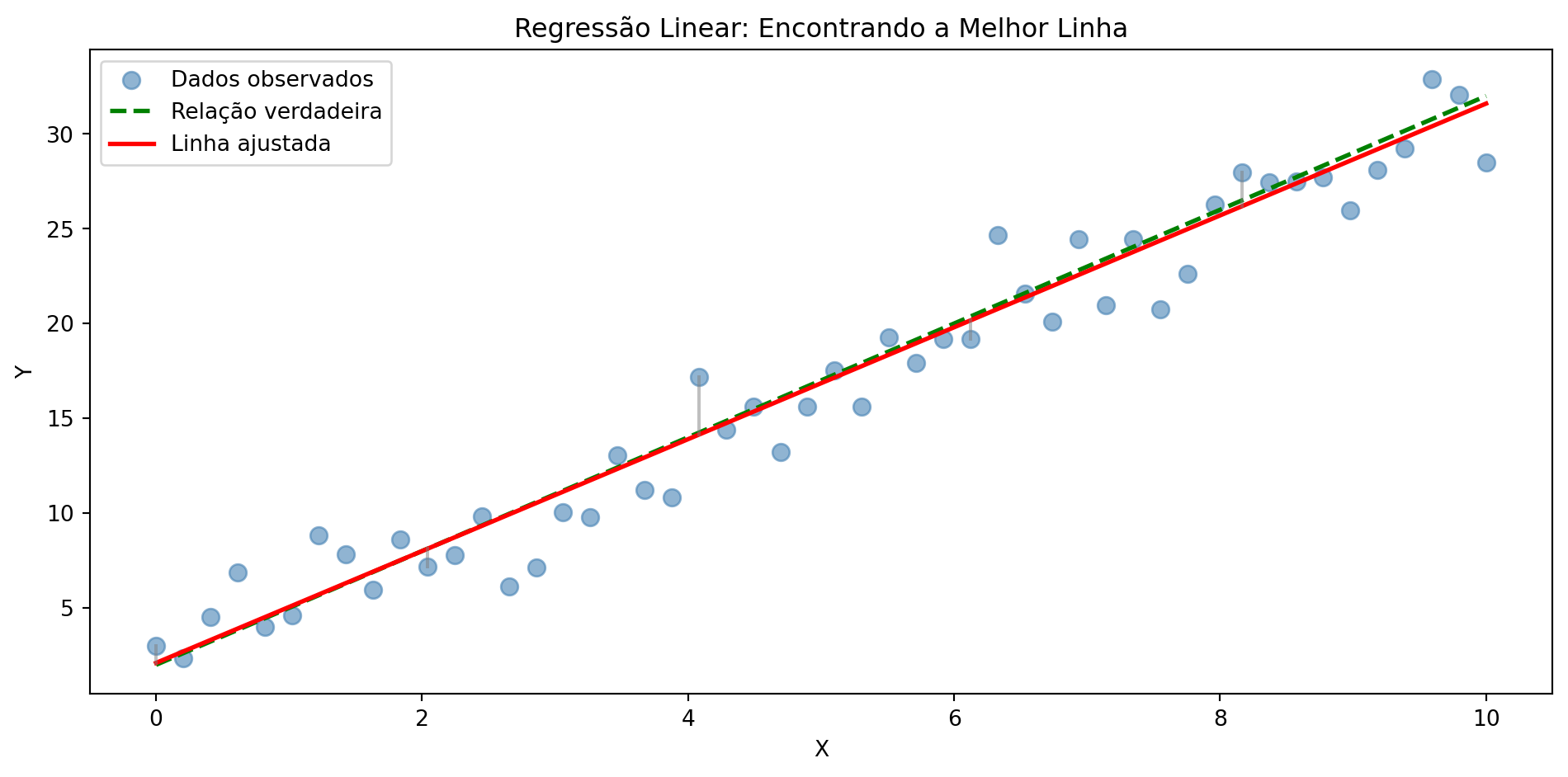
Essa melhor linha se chama: RETA DE REGRESSÃO
Encontrando a Melhor Reta
O processo matemático minimiza as distâncias dos pontos à linha
Definindo o Problema Matematicamente
Para os pinguins:
- x = comprimento da nadadeira (variável explicativa)
- y = massa corporal (variável resposta)
Para cada pinguim, temos um erro: \((y - \hat{y})^2\)
Onde:
- y: massa corporal real observada
- ŷ: nossa melhor estimativa/chute para aquele pinguim
Objetivo: Fazer o menor erro possível!
A Função de Predição
Nossa estimativa ŷ é uma função dos dados que temos:
\[ \hat{y} = f(x) \]
Em termos práticos:
- Entrada: dados do pinguim (comprimento da nadadeira)
- Saída: peso estimado
- f(x): nossa “fórmula mágica” para fazer a predição
Pergunta: Qual deve ser essa função f(x)?
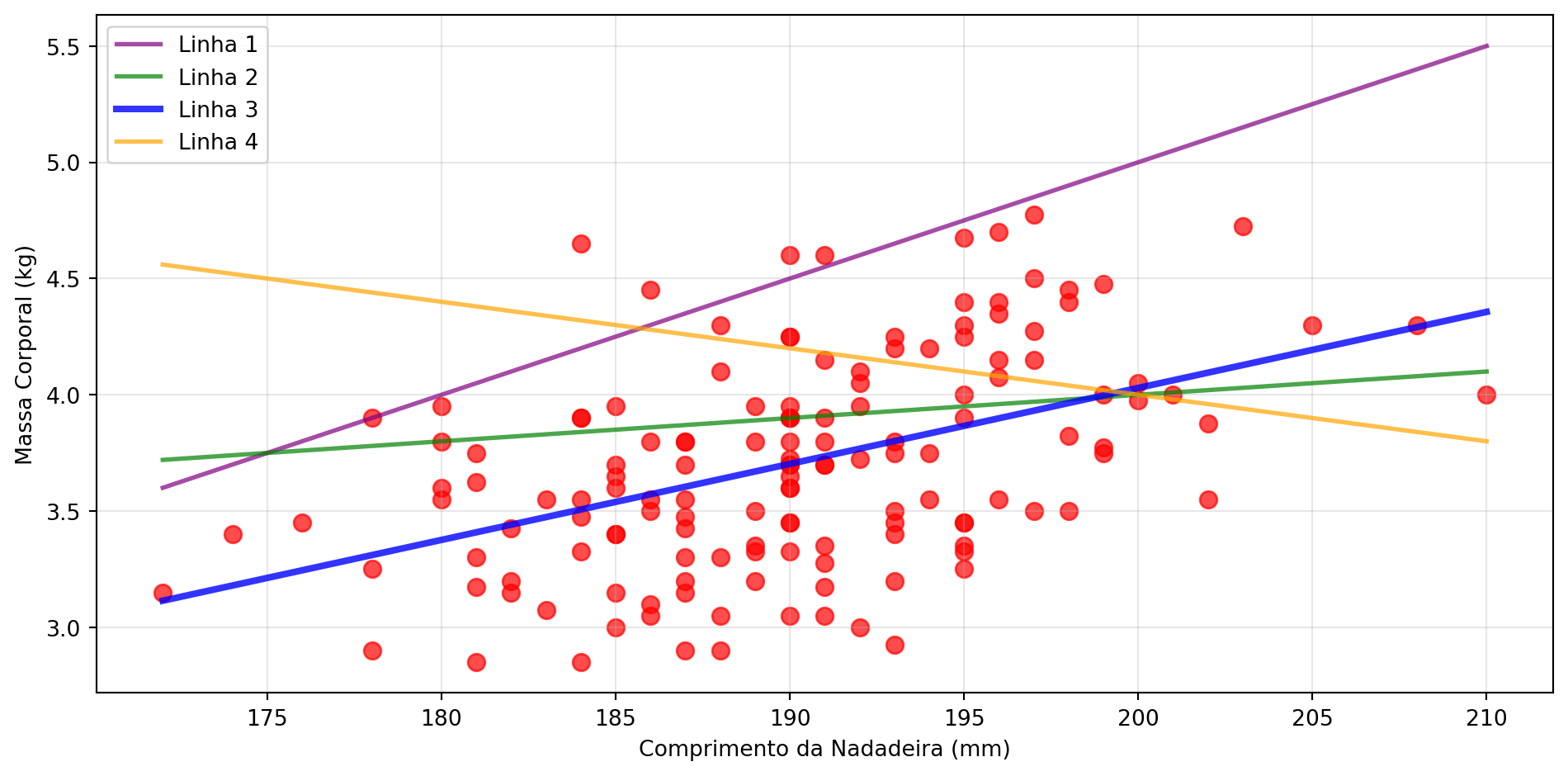
Tipos de Funções Possíveis - Linear
\[ f(x) = a + bx \]
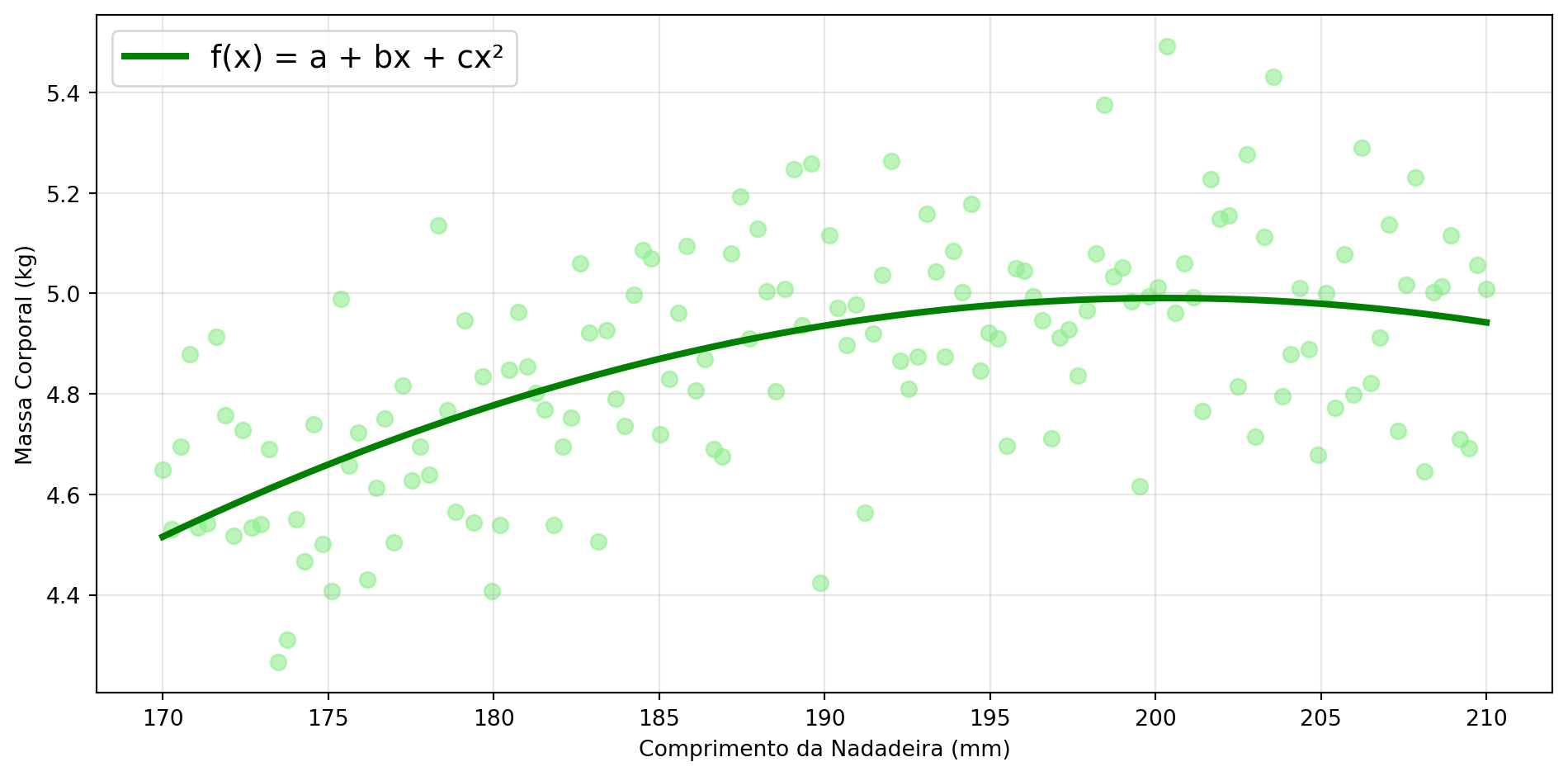
Tipos de Funções Possíveis - Quadrática
\[ f(x) = a + bx + cx^2 \]
Tipos de Funções Possíveis - Cúbica
\[ f(x) = a + bx + cx^2 + dx^3 \]
Escolhendo os Melhores Parâmetros
Cada função tem parâmetros que precisam ser determinados:
- Linear: a, b
- Quadrática: a, b, c
- Cúbica: a, b, c, d
Como escolher os valores?
- Os parâmetros são escolhidos através de um processo matemático que minimiza as distâncias dos pontos à curva de regressão (ex: mínimos quadrados)
- Resultado: os menores erros possíveis frente aos dados que temos
Regressão Linear Simples
Equação básica: \[ Y = \beta_0 + \beta_1 X + \varepsilon \]
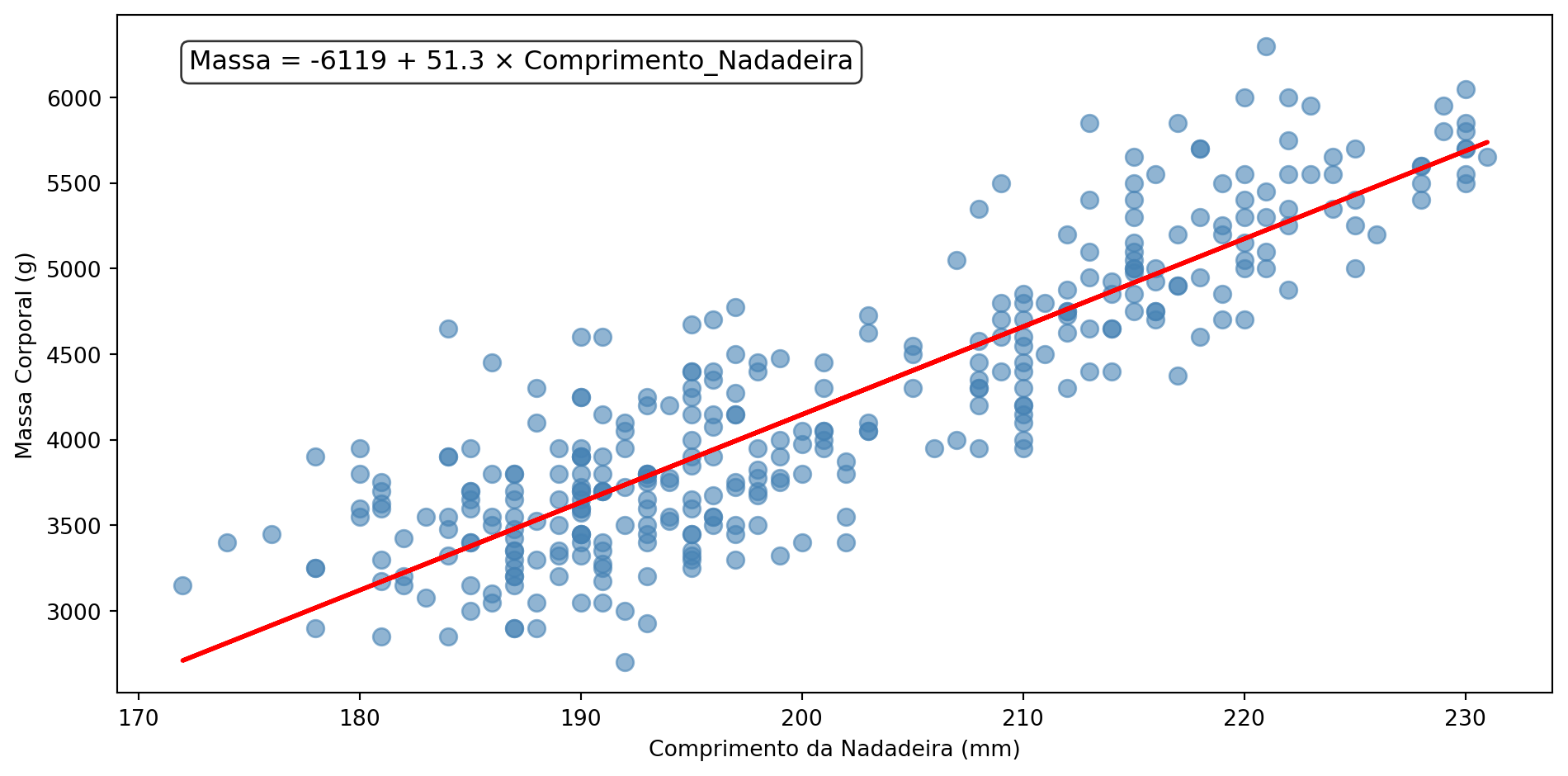
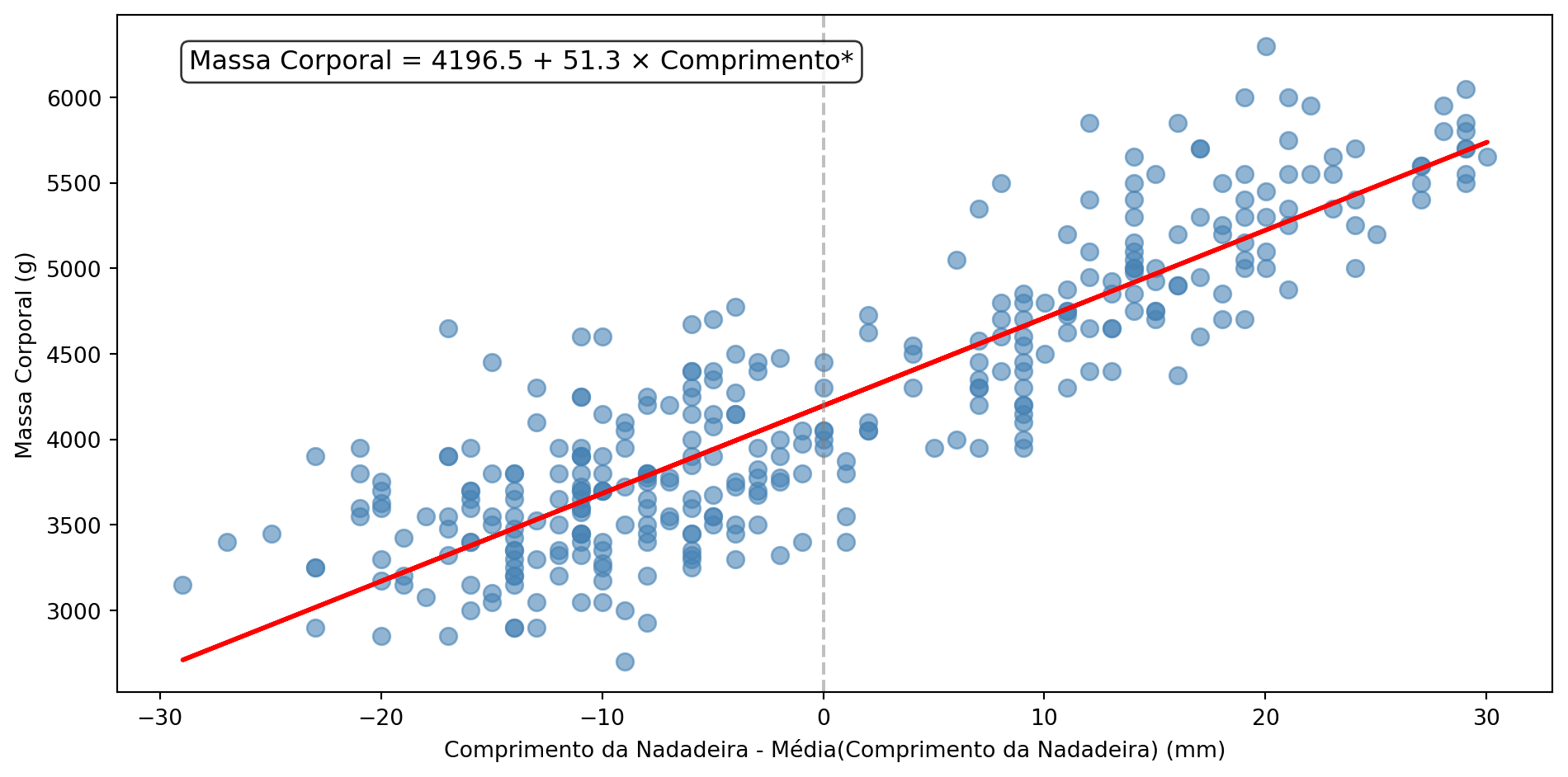
- β₀: intercepto (valor de Y quando X = 0)
- β₁: inclinação (mudança em Y para cada unidade de X)
- ε: erro aleatório
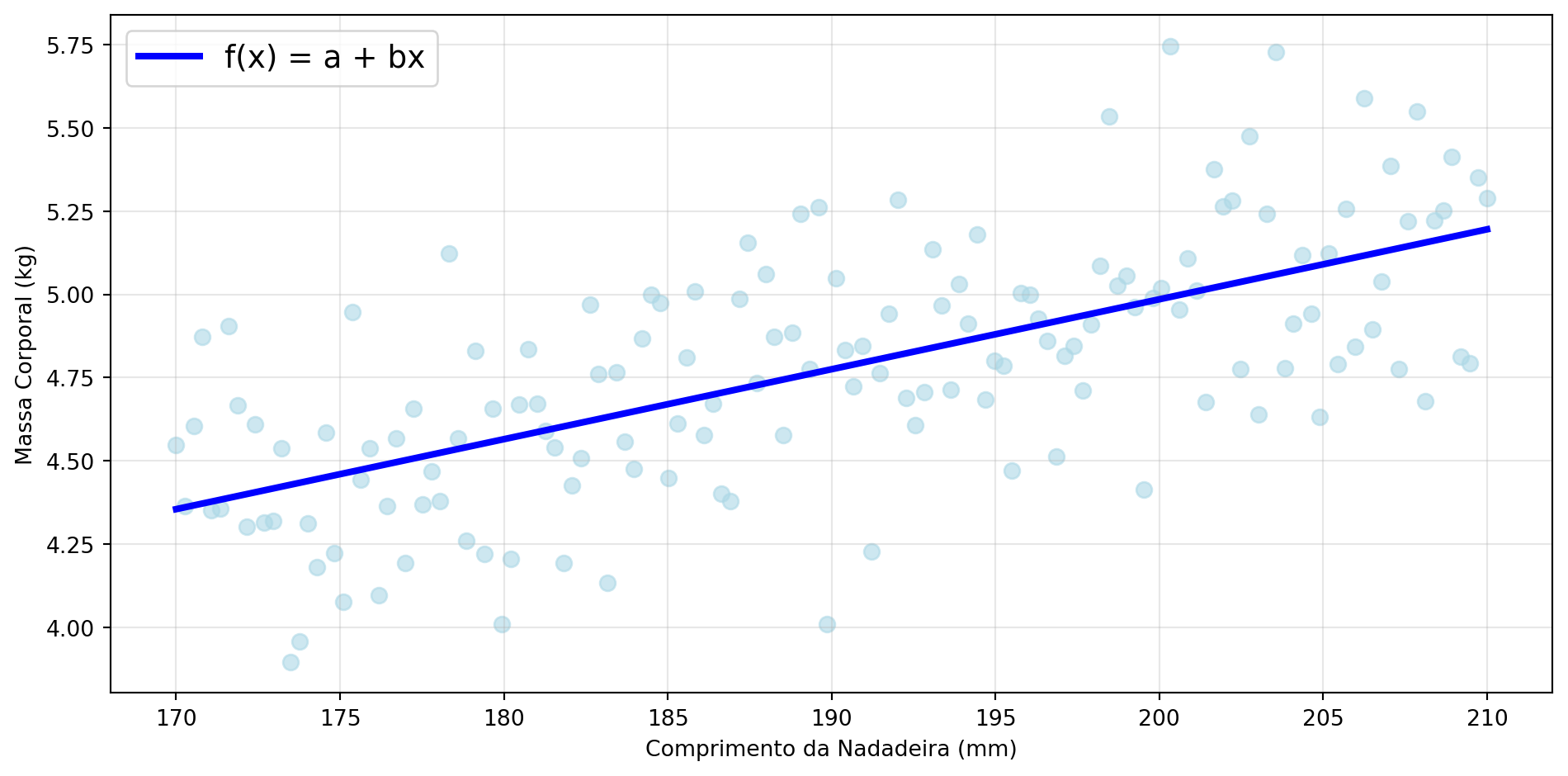
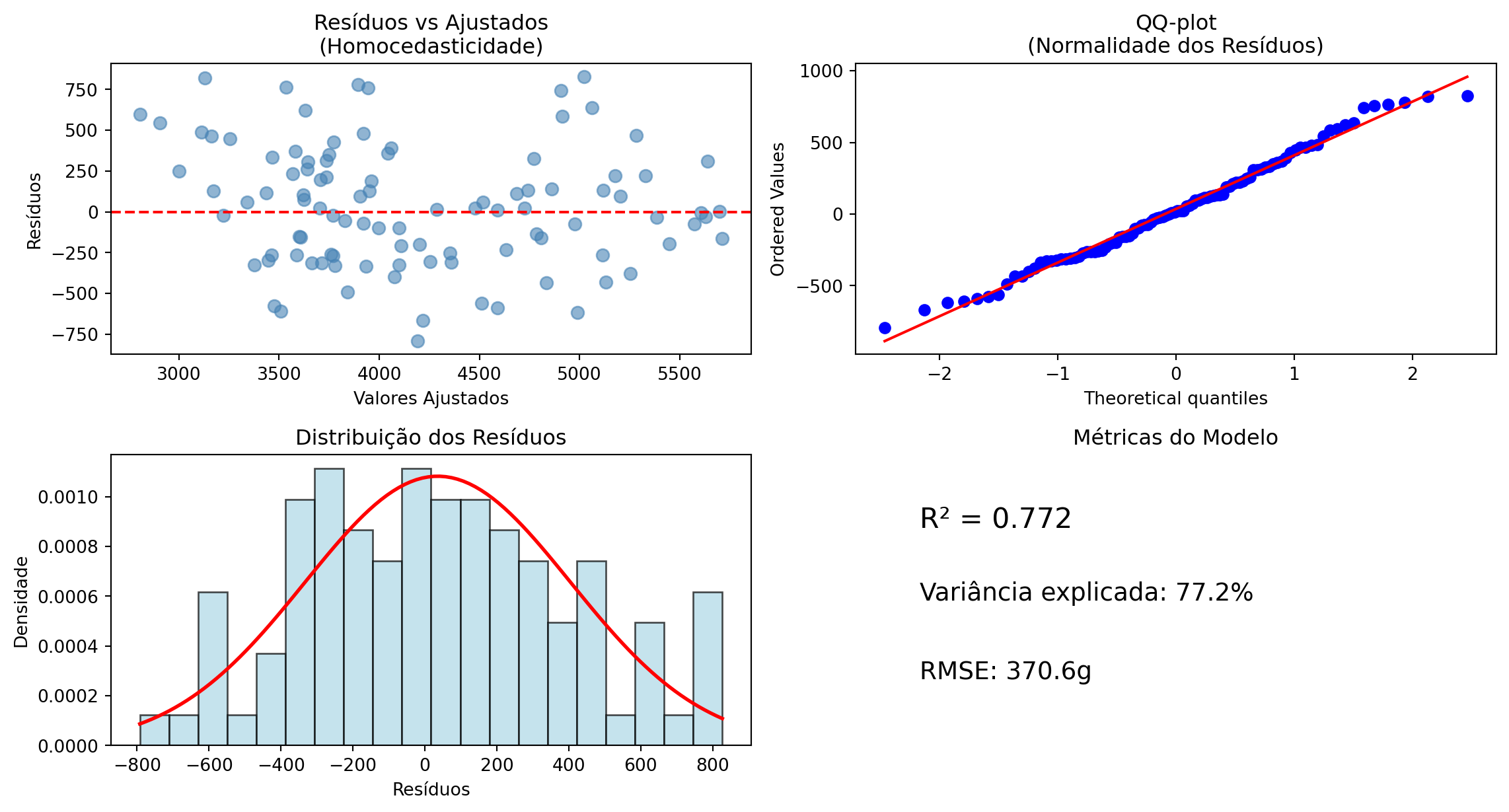
Regressão Linear na Prática
Interpretação: Para cada mm adicional na nadadeira, o pinguim ganha aproximadamente 51g de massa
Regressão Linear Múltipla
Quando temos múltiplas variáveis explicativas:
\[ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + ... + \beta_n X_n + \varepsilon \]
Podemos prever a Massa Corporal utilizando todas as outras variáveis do conjunto de dados!
- Quanto mais informação, menor a incerteza sobre o fenômeno
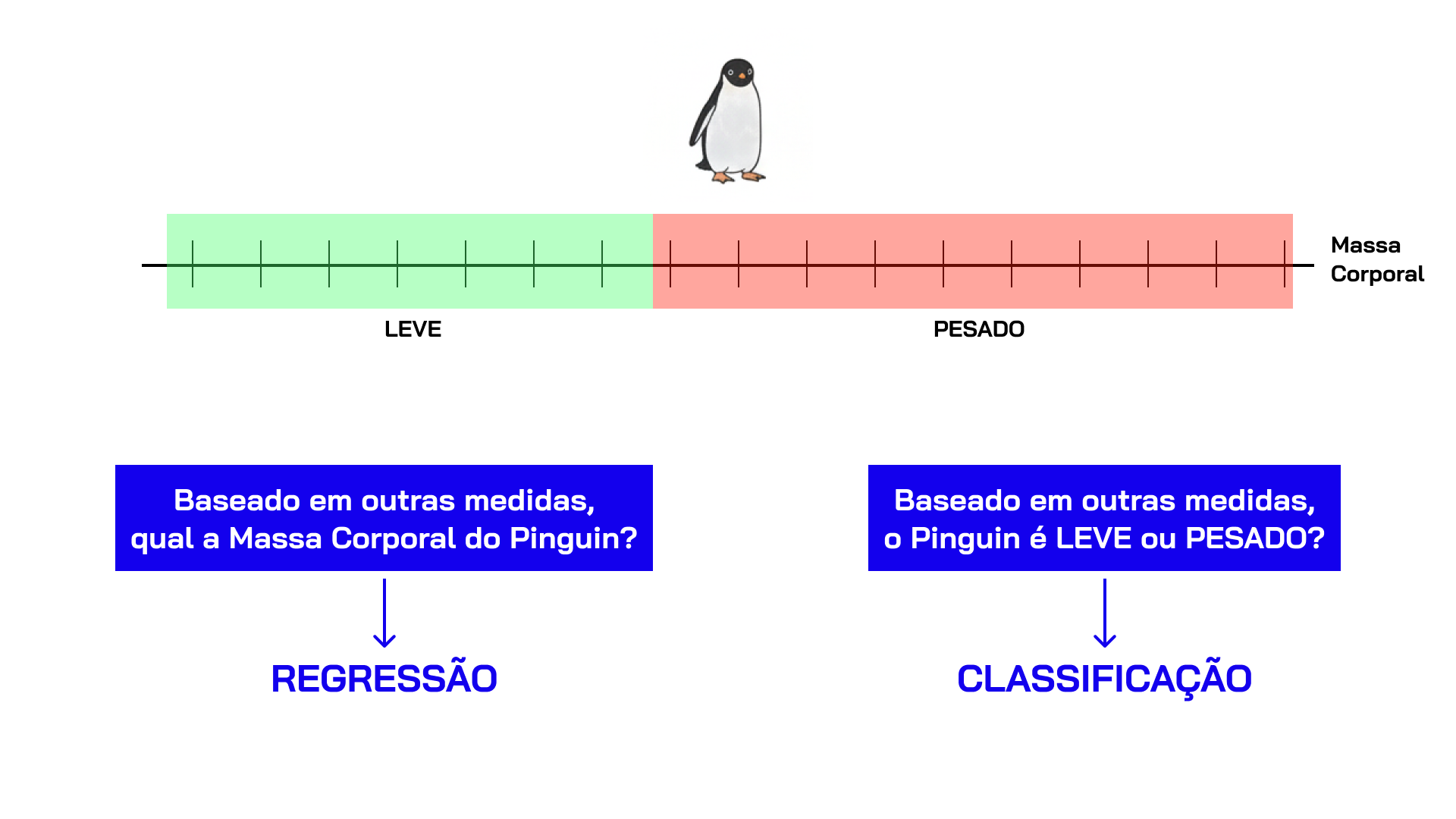
Quando Usar Regressão Logística?
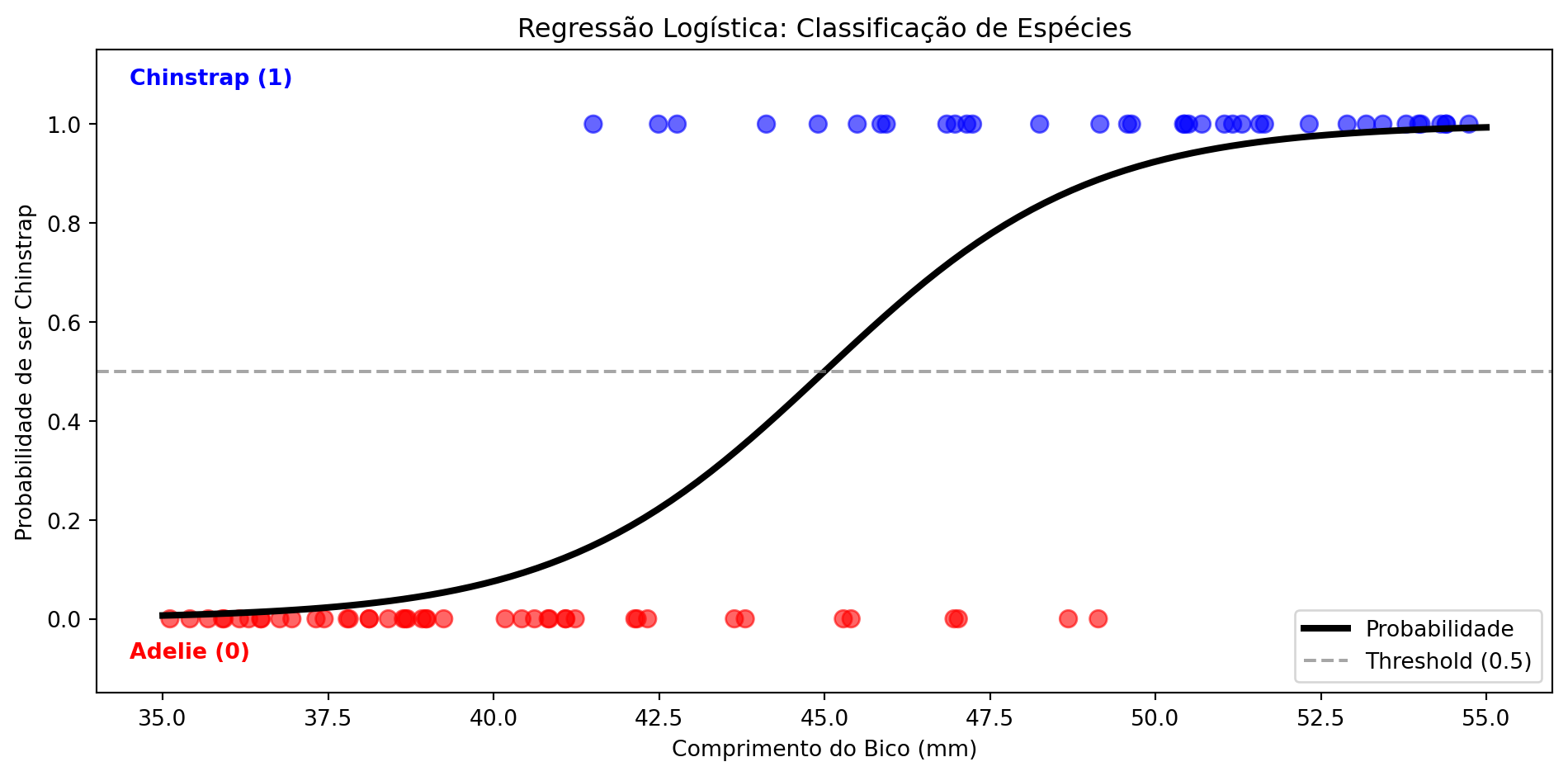
Para problemas de classificação (não regressão!):
Diferença: Saída é probabilidade (0 a 1)
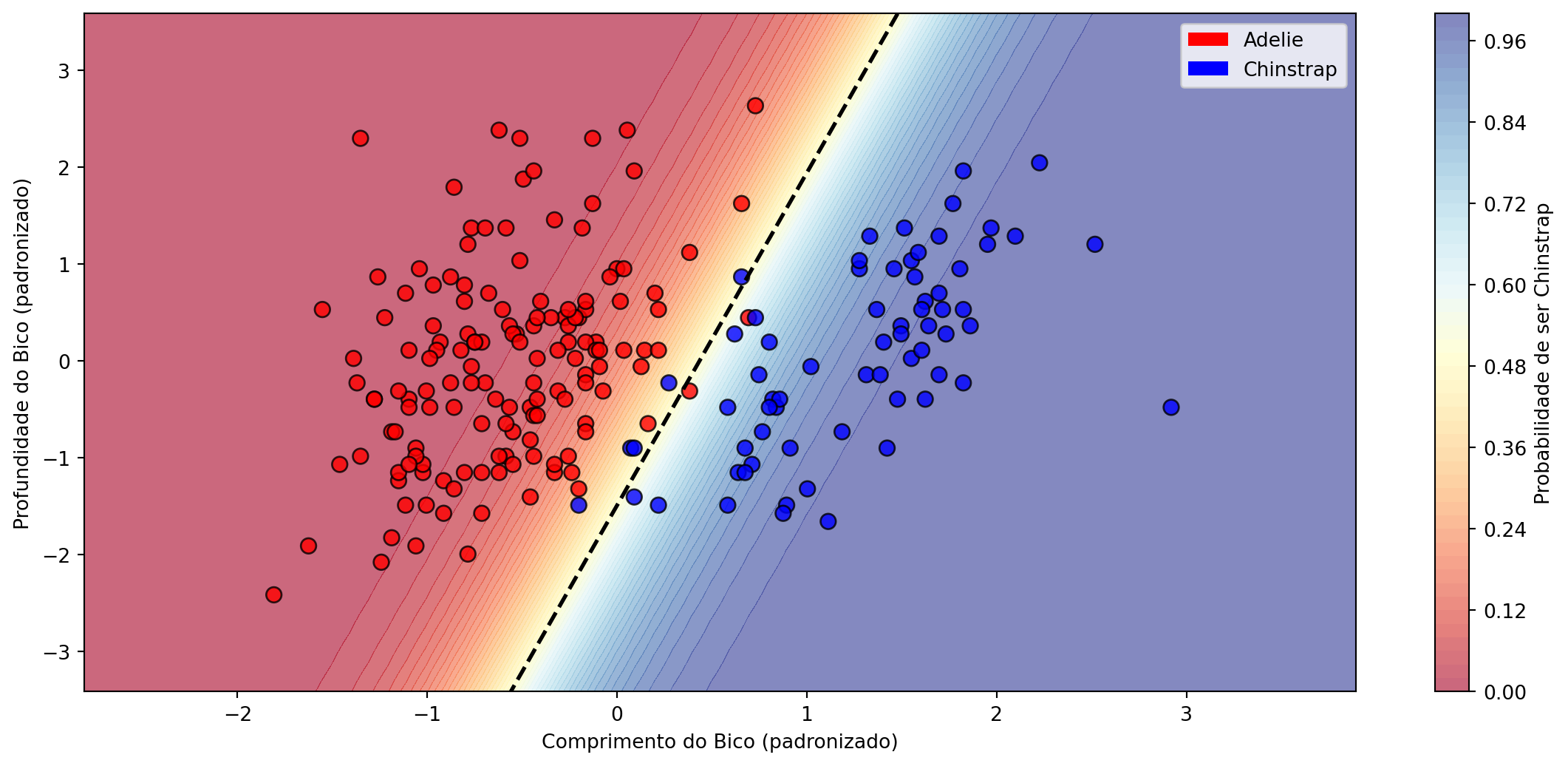
Regressão Logística na Prática
Fronteira de decisão: Linha preta tracejada separa as duas classes
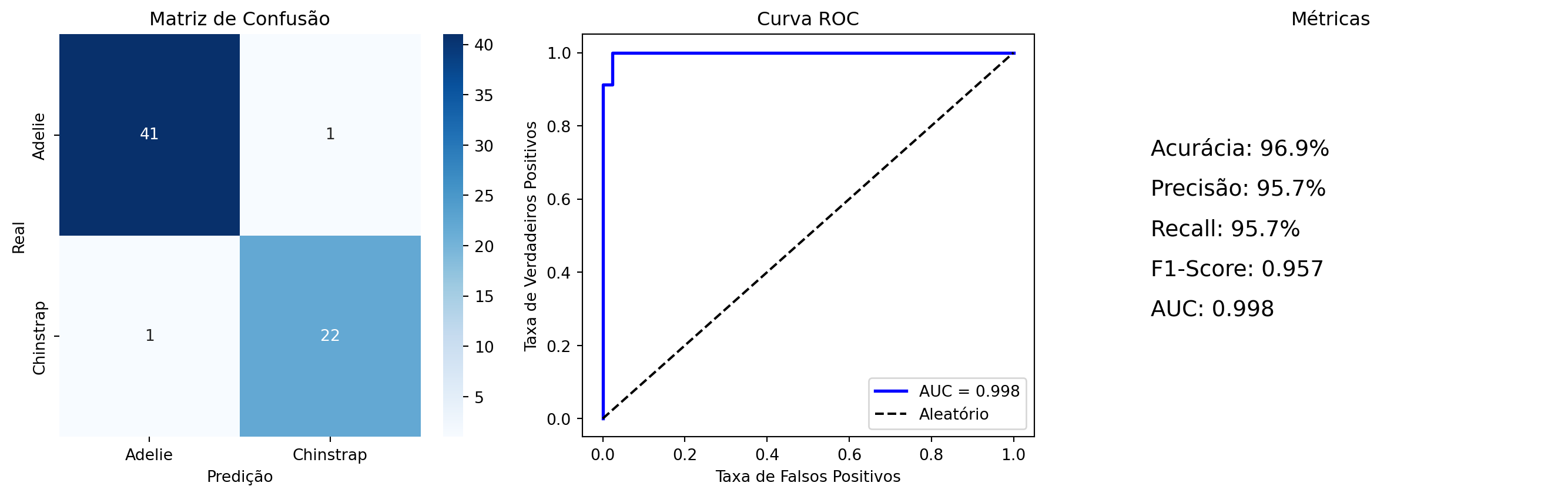
Avaliação de Modelos de Classificação
Métricas-chave: Acurácia, Precisão, Recall, F1-Score, AUC-ROC
Interpretando as Métricas no Contexto
Para classificação de pinguins Adelie vs Chinstrap:
- Acurácia: Quantos pinguins foram classificados corretamente
- “De 100 pinguins, acertamos a espécie de 85”
- Precisão: Dos que dissemos ser Chinstrap, quantos realmente são?
- “Das vezes que dissemos ‘é Chinstrap’, acertamos 90%”
- Recall: Dos Chinstraps reais, quantos conseguimos identificar?
- “Dos Chinstraps que existiam, encontramos 80%”
- F1-Score: Média harmônica entre Precisão e Recall
- “Equilíbrio entre não errar e não perder pinguins”
Pausa de 10 minutos
Link do Notebook para o Hands-on
Aprendizado
Não-supervisionado
Descobrindo Padrões Ocultos
“Já se perguntou como o Spotify consegue agrupar músicas por ‘vibe’ mesmo sem você dizer qual é o gênero?”
Nesses casos NÃO temos uma variável de interesse conhecida
- Supervisionado: “Ensine-me com exemplos corretos”
- Não-supervisionado: “Encontre padrões que eu não vejo”
Duas tarefas comuns:
- Redução de Dimensionalidade: Simplificar dados complexos
- Clustering: Descobrir grupos naturais
Por que Precisamos Dessas Técnicas?
Problema 1: Dados com muitas variáveis são difíceis de visualizar
- Como plotar 10 variáveis de pinguins em um gráfico?
Problema 2: Nem sempre sabemos quais grupos existem nos dados
- Existem subgrupos dentro das espécies?
- Como descobrir padrões que não esperávamos?
Solução: Algoritmos que encontram estruturas ocultas nos dados
O Desafio da Visualização
“Como observar dados com 4, 10 ou 100 dimensões?” 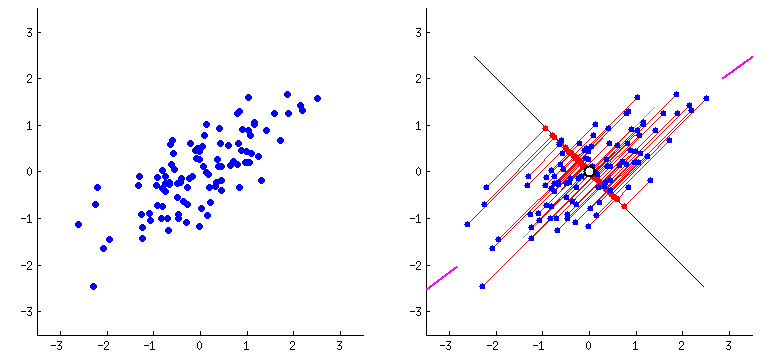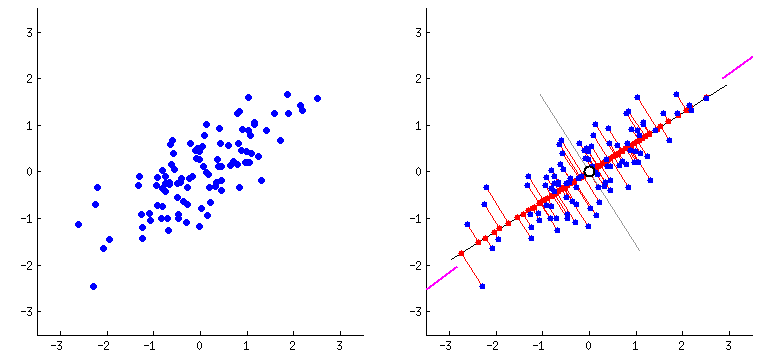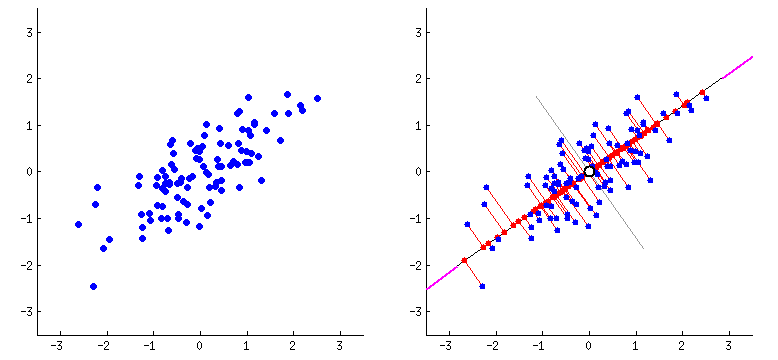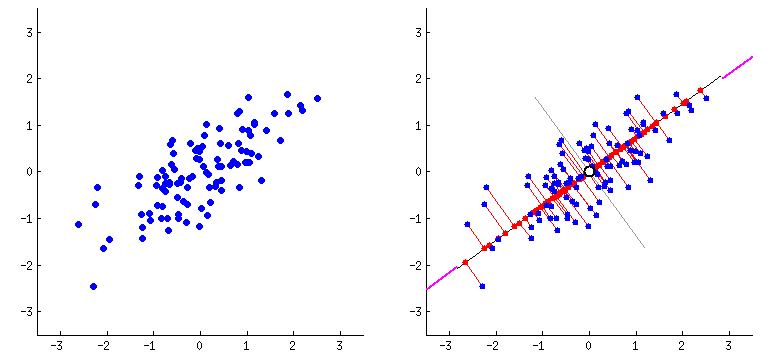
PCA (Principal Component Analysis): Encontra as “melhores direções” para observar os dados
Ideia central: Capturar o máximo de informação em poucas dimensões
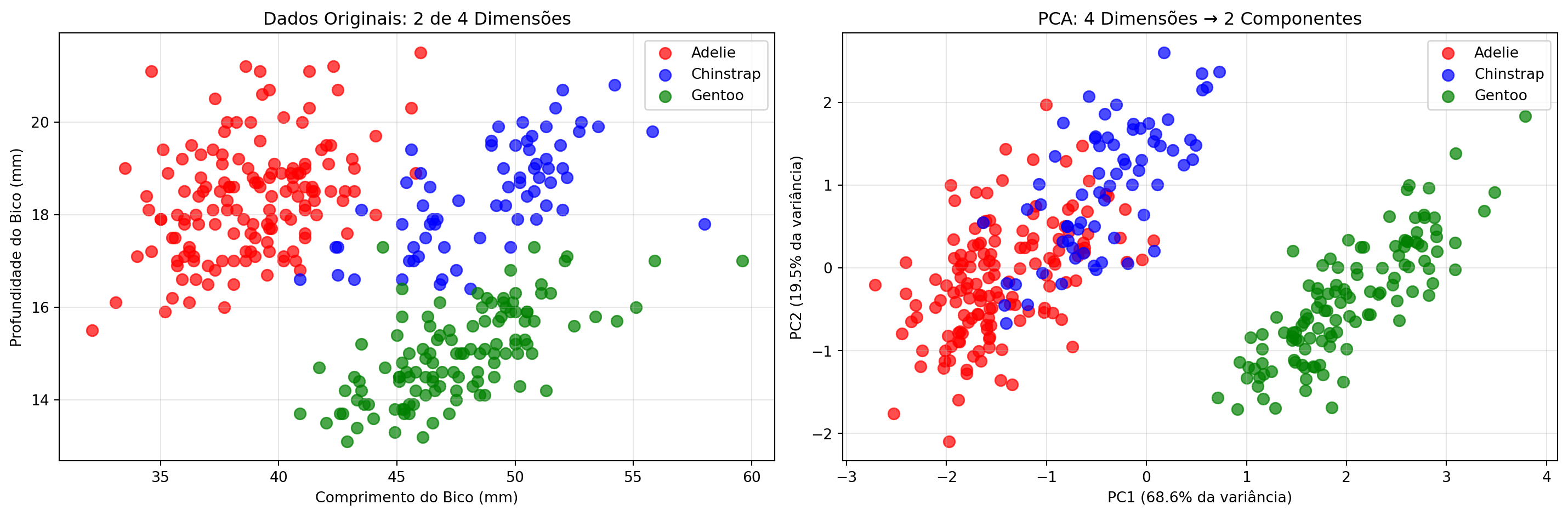
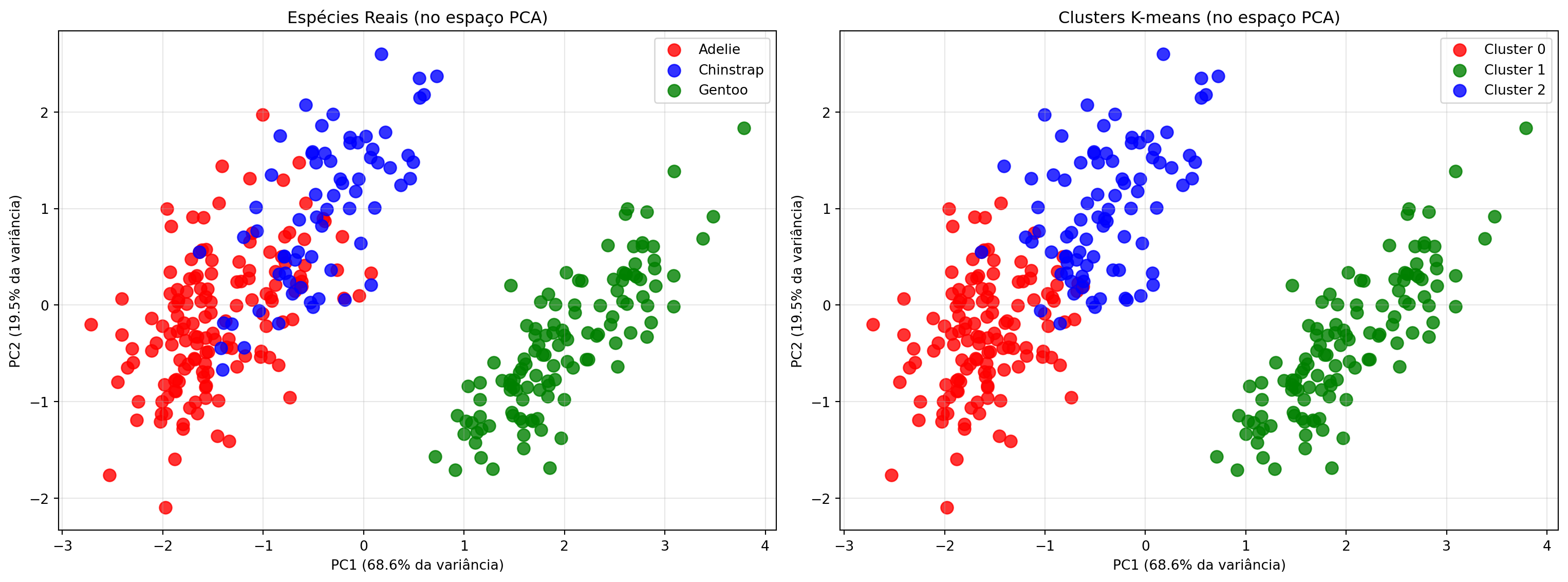
PCA na Prática: 4 → 2 Dimensões
Mantivemos ~88% da informação original com apenas 2 componentes!
Como o PCA Funciona?
Padronizar os dados (todas as variáveis na mesma escala)
Encontrar a direção de maior variação (PC1)
- “Por onde os dados se espalham mais?”
Encontrar a segunda direção perpendicular (PC2)
Repetir até ter todos os componentes
Resultado: Novos “eixos” que capturam o máximo de informação
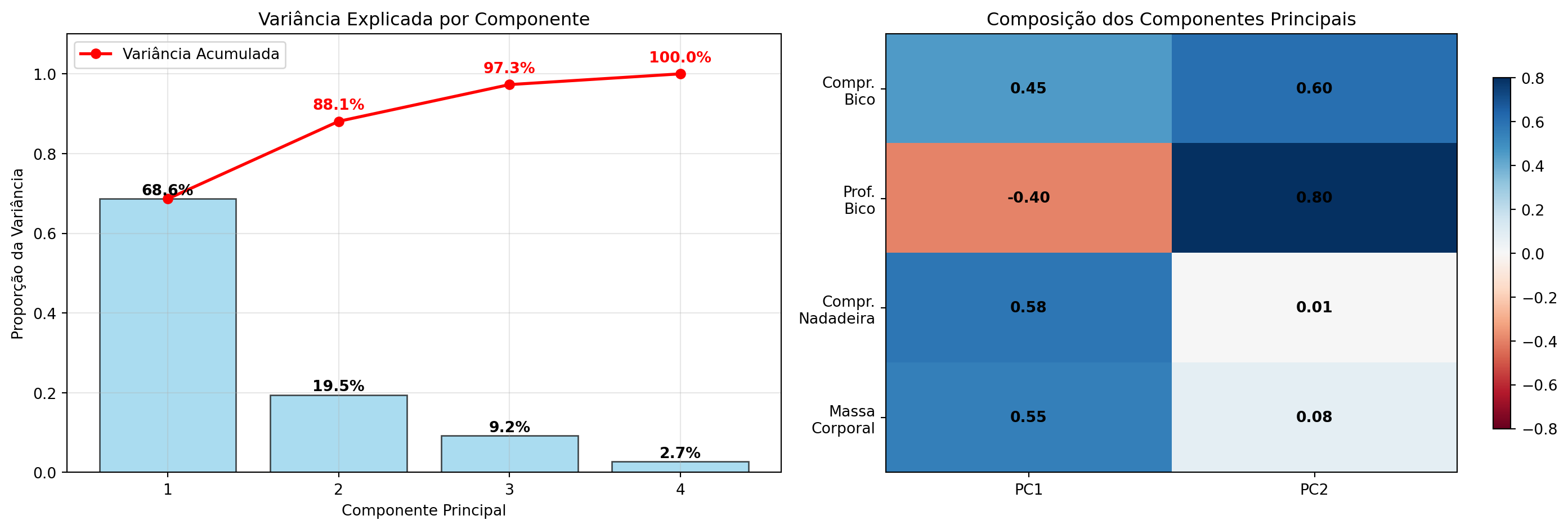
Interpretando os Componentes Principais
PC1 (68,6%): Tamanho geral do pinguim
PC2 (19,5%): Características específicas do bico
Utilizando 3 Componentes Principais
~97% da variância total dos dados, com uma variável a menos
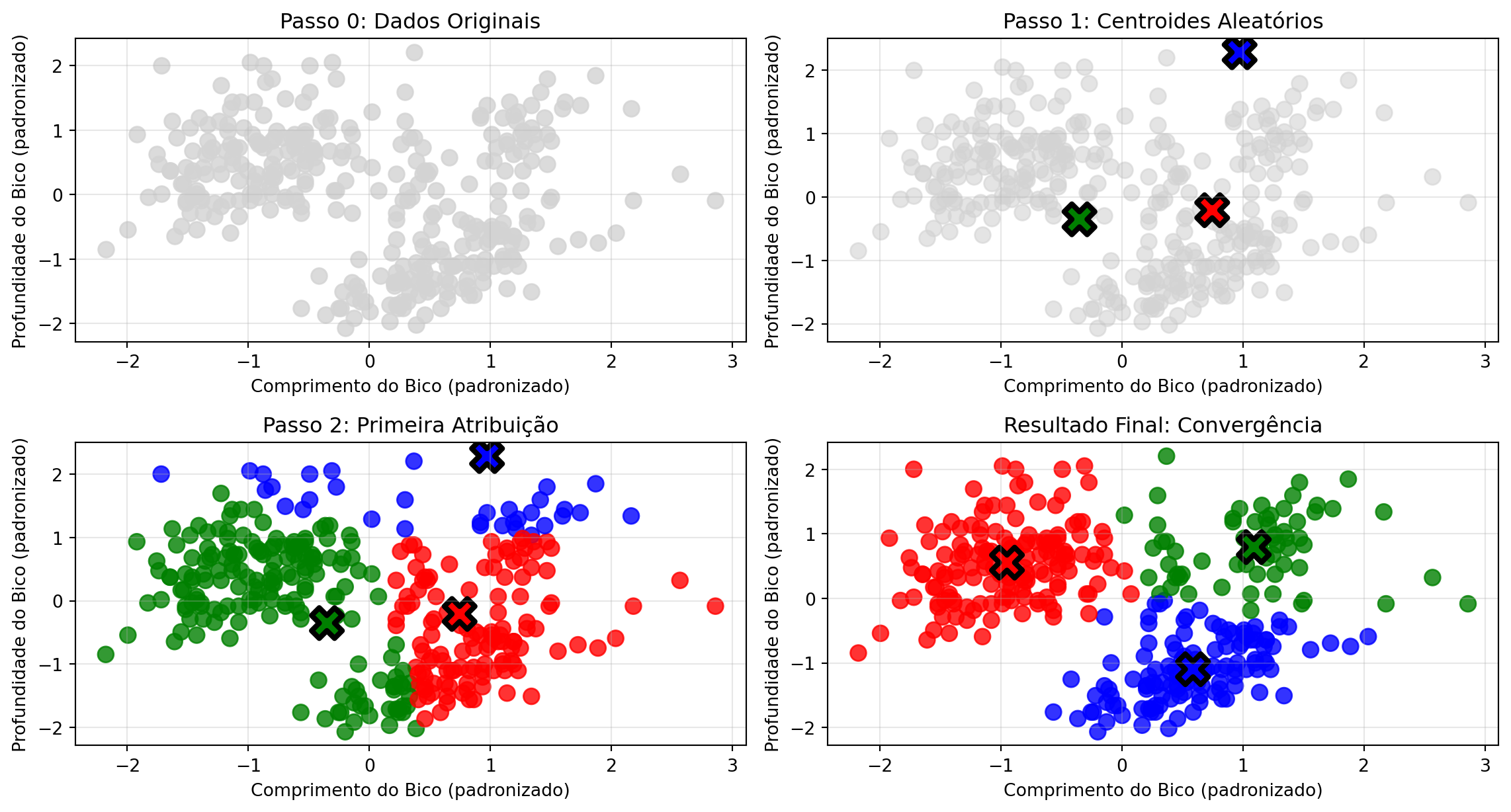
O Problema da Organização
“Imagine que você precisa organizar uma gaveta cheia de objetos misturados, mas sem instruções de como agrupá-los.” 
O Algoritmo K-means Passo a Passo
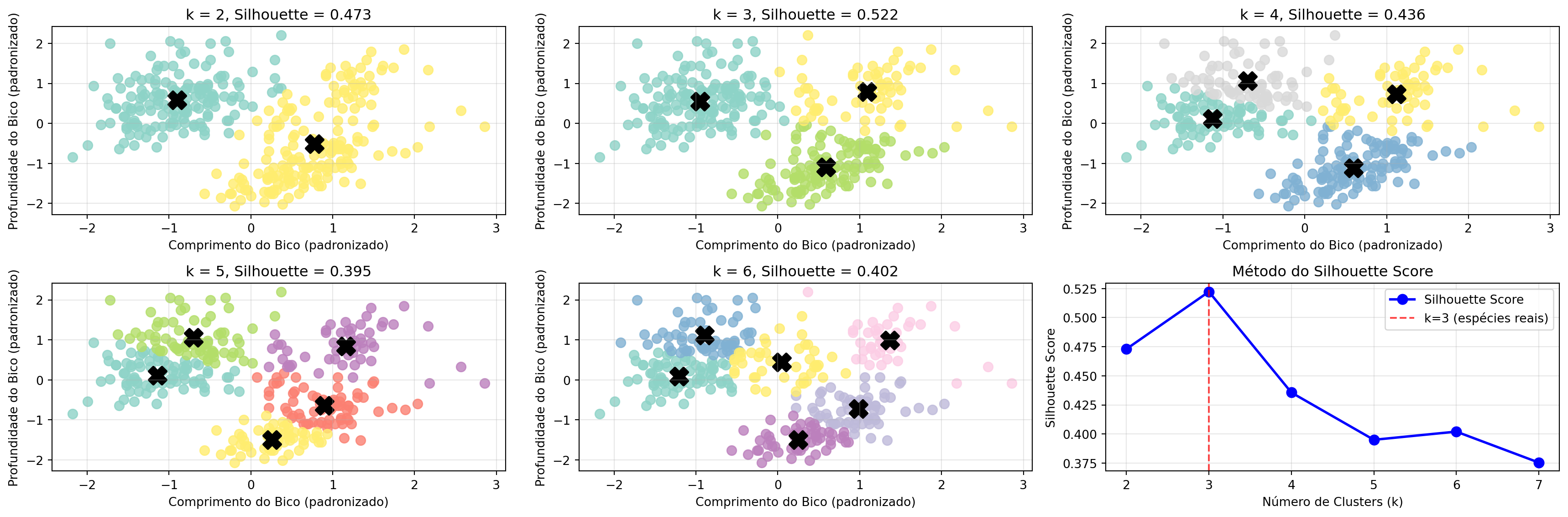
Avaliando a Qualidade dos Clusters
“Como sabemos se o agrupamento faz sentido?”
Pausa de 10 minutos
Link do Notebook para o Hands-on