Quando analisamos dados, nem sempre conseguimos saber com certeza o valor exato de uma característica da população, como a média de idade de todos os brasileiros, pois para ter tal informação com exatidão, seria preciso entrevistar todos os brasileiros. Em vez disso, usamos uma amostra e a usamos para construir um intervalo de confiança: uma faixa de valores que provavelmente contém o valor verdadeiro.
Neste módulo, você vai aprender:
O que são intervalos de confiança e como interpretá-los;
Como calcular intervalos de confiança para médias e proporções;
Como visualizar e aplicar esses conceitos com Python.
Definições Básicas
Antes de falarmos sobre intervalos de confiança, é importante entender alguns conceitos fundamentais da estatística.
População: A população é o conjunto completo de elementos sobre o qual queremos tirar conclusões. Geralmente é difícil (ou impossível) observar todos os seus membros.
Exemplo: Todas as pessoas adultas que moram no Brasil.
Amostra: Uma amostra é um subconjunto da população. É a parte que conseguimos observar ou medir e a usamos para tirar conclusões sobre a população.
Exemplo: Um grupo de 100 adultos escolhidos aleatoriamente em várias cidades do Brasil.
Estatística: Uma estatística é uma função da amostra — como média, proporção ou desvio padrão.
Exemplo: A média de idade dos 100 adultos da amostra.
Estimativa: Uma estimativa é o valor da estatística usado como aproximação de um valor da população. Ela sempre vem acompanhada de alguma incerteza.
Exemplo: Usar a média da amostra para estimar a idade média real de todos os adultos no Brasil.
Parâmetro: Um valor fixo que descreve uma característica da população inteira.
Exemplo: A verdadeira média de idade de todos os adultos no Brasil.
Nota
Em um estudo tiramos um Amostra de uma População, identificamos a Estatística referente ao Parâmetro de interrese e calculamos sua Estimativa.
O que é um Intervalo de Confiança?
Imagine que você queira saber a média da idade de parte específica da população brasileira. Você faz uma pesquisa com 100 pessoas e encontra uma média de aproximadamente 29 anos. Mas será que isso representa todos os brasileiros? Provavelmente não exatamente. Por isso, calculamos um intervalo de confiança.
Intervalo de Confiança (IC) é um intervalo que, com determinada certeza (ex: 95%), contém o valor verdadeiro da população. Ele mostra a incerteza natural que existe ao trabalhar com uma amostra.
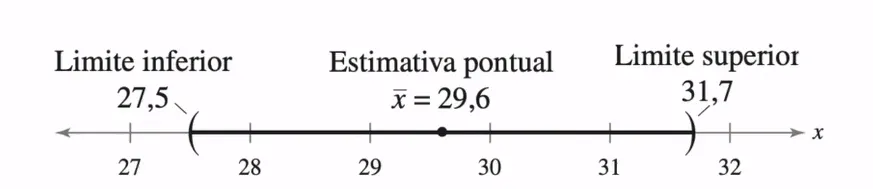
Exemplo de um intervalo de confiança para a média
Olhando para esta figura conseguimos identificar alguns conceitos importantes do intervalo de confiança:
Estimativa pontual: é a média da nossa amostra;
Limite inferior e superior: valores limites que formam o intervalo de confiança. Eles são simétricos com relação a estimativa pontual.
Aviso
Cada intervalo possui pressupostos que precisam ser atendidos antes de ser calculado. Se esses pressupostos não forem atendidos, os resultados podem ser enganosos.
Como Interpretar?
Se você obteve um intervalo de [27.5, 31.7] para a média de idade, isso significa que há 95% de confiança de que o valor verdadeiro da população está dentro desse intervalo.
Isso não significa que a probabilidade de o valor estar dentro do intervalo seja 95% (essa interpretação é comum, mas não exata). Significa que se você repetisse o estudo 100 vezes, você terá 100 intervalos diferentes, um para cada repetição do estudo. E desses 100, 95% dos intervalos gerados conteriam o valor verdadeiro.
Tamanho da Amostra
Para contruir um intervalo é preciso de uma amostra, e o tamanho dessa amostra vai influenciar diretamente no tamanho do intervalo. Uma amostra grande aumenta nossa confiança e diminui o intervalo, já uma amostra pequena diminui nossa confiança e aumenta o intervalo. No geral, a literatura indica que, uma amostra de tamanho 30 ou maior já pode ser considerada como seguindo a distribuição normal, para a construção dos intervalos.
Intervalo de Confiança para a Média
Usamos a função t.interval da biblioteca scipy.stats.
Exemplo
Vamos continuar com o exemplo da idade. Você coleta as idades de 50 pessoas e obtém uma média de 45 anos, e você está interessado em uma análise intervalar.
Pressupostos:
Dados contínuos;
Amostra aleatória;
Os dados devem seguir distribuição normal.
import numpy as npfrom scipy import statsnp.random.seed(42)dados = np.random.normal(loc=50, scale=5, size=30)media = np.mean(dados)desvio_padrao = np.std(dados, ddof=1)n =len(dados)# Intervalo de confiança de 95% usando t.intervalic_inferior, ic_superior = stats.t.interval( confidence=0.95, # nível de confiança df=n-1, # graus de liberdade loc=media, # média da amostra scale=desvio_padrao / np.sqrt(n) # erro padrão da média)print(f"Média: {media:.2f}")print(f"Intervalo de confiança (95%): [{ic_inferior:.2f}, {ic_superior:.2f}]")
Média: 49.06
Intervalo de confiança (95%): [47.38, 50.74]
A saída mostra um intervalo entre 47,4 e 51,0 anos — essa é a estimativa para a faixa de idade na qual acreditamos que a média da população está.
Intervalo de Confiança para Diferença de Médias
Exemplo
Agora queremos saber a diferença de idade entre homens e mulheres da população brasileira. Algum dos grupos tem um média maior? Ou eles têm médias iguais
Pressupostos:
Amostras independentes;
Dados aproximadamente normais em cada grupo;
Variâncias semelhantes (para uso do método padrão).
Diferença entre médias: 4.89
Intervalo de confiança (95%): [2.63, 7.14]
Com esse tipo de intervalo estamos interessados se o 0 está incluido no intervalo. Se o 0 estiver incluido no intervalo de confiança podemos dizer que não existe diferença significativa entre os dois grupos pesquisados. Nesse caso, o intervalo não contem o 0, portanto afirmamos que as médias entre homens e mulheres são diferentes.
Também estamos interessados no sinal do intervalo: intervalos positivos indicam que o Grupo 1 (homens) tem a média maior que o Grupo 2 (mulheres); mas intervalo negativos indicam o contrário. Nesse caso, o intervalo é positivo, então os homens possuem a maior média, quando comparado com as mulheres.
Intervalo de Confiança para Proporção
Exemplo:
Queremos saber a proporção de pessoas do nosso grupo de estudo que tem 50 anos ou mais.
Pressupostos:
Amostra aleatória;
Tamanho da amostra grande o suficiente (np > 5 e n(1-p) > 5).
Existem dois métodos usados nos intervalo de confiança para proporção, normal e wilson:
Normal
É o método tradicional que usa a aproximação normal para calcular o intervalo em torno da proporção amostral. Assume que a distribuição da proporção é aproximadamente normal. Útil com amostras “grandes” (n ≥ 30) e proporções longe de 0 ou 1.
import numpy as npfrom statsmodels.stats.proportion import proportion_confint# Amostra simuladanp.random.seed(42)idades = np.random.normal(loc=50, scale=5, size=30)# Contando quantos têm 50 anos ou maissucessos = np.sum(idades >=50)total =len(idades)proporcao = sucessos / total# Intervalo de confiança com método normal approximationic_inf, ic_sup = proportion_confint( count=sucessos, nobs=total, alpha=0.05, method='normal'# ou 'wilson' para uma alternativa mais robusta)print(f"Proporção estimada (50+): {proporcao:.2%}")print(f"Intervalo de confiança (95%): [{ic_inf:.2%}, {ic_sup:.2%}]")
Proporção estimada (50+): 40.00%
Intervalo de confiança (95%): [22.47%, 57.53%]
Com base na nossa amostra, estimamos que 40% das pessoas têm 50 anos ou mais. O intervalo de confiança indica que, se repetíssemos esse processo com várias amostras, em 95% dos casos a proporção verdadeira na população estaria entre 22,47% e 57,53%.
Wilson
Baseia-se no intervalo score (ou intervalo score de Wilson), que ajusta a simetria do intervalo em torno da proporção, tornando-o mais preciso. Recomendado na maioria dos casos, incluindo amostras pequenas e proporções próximas de 0 ou 1.
# Intervalo de confiança com método Wilsonic_inf, ic_sup = proportion_confint( count=sucessos, nobs=total, alpha=0.05, method='wilson'# ou 'normal' para uma alternativa menos robusta)print(f"Proporção estimada (50+): {proporcao:.2%}")print(f"Intervalo de confiança (95%): [{ic_inf:.2%}, {ic_sup:.2%}]")
Proporção estimada (50+): 40.00%
Intervalo de confiança (95%): [24.59%, 57.68%]
Apesar do seu intervalo mudar em relação ao outro método, sua interpretação é a mesma do intervalo com o método normal.
Intervalo de Confiança para Diferença de Proporções
Exemplo:
Agora vamos comparar a proporção de pessoas com 30+ entre homens e mulheres
Pressupostos:
Amostras independentes;
np e n(1-p) > 5 em ambos os grupos.
Para a diferença de proporções também temos dois métodos, wald e score
Wald
from statsmodels.stats.proportion import confint_proportions_2indep# Simulando dadosnp.random.seed(123)idade_homens = np.random.normal(52, 7, 60)idade_mulheres = np.random.normal(48, 7, 60)# Binarizandoh50 = idade_homens >=50m50 = idade_mulheres >=50# Contagenssucessos_h = h50.sum()sucessos_m = m50.sum()# Intervalo de confiança da diferença de proporçõesic_inf, ic_sup = confint_proportions_2indep( count1=sucessos_h, nobs1=len(h50), count2=sucessos_m, nobs2=len(m50), method='wald'# também pode usar 'score' (mais robusto))# Diferença de proporções estimadaph = sucessos_h /len(h50)pm = sucessos_m /len(m50)dif = ph - pmprint(f"Proporção H (50+): {ph:.2%}")print(f"Proporção M (50+): {pm:.2%}")print(f"Intervalo de confiança da diferença: [{ic_inf:.2%}, {ic_sup:.2%}]")
Proporção H (50+): 58.33%
Proporção M (50+): 38.33%
Intervalo de confiança da diferença: [2.48%, 37.52%]
A diferença observada entre os sexos é de 20 pontos percentuais, com os homens apresentando uma maior proporção de pessoas com 50 anos ou mais. O intervalo de confiança nos diz que, com 95% de confiança, a diferença verdadeira entre homens e mulheres está entre 2,48% e 37,52%.
Como o intervalo não contém zero, há evidência de que a diferença entre os grupos pode ser real (ou seja, não é apenas por acaso nessa amostra específica).
Score
É uma extensão do Wilson para comparação entre duas proporções. Também chamado de intervalo de Newcombe ou score modificado. É o método mais confiável para diferenças de proporções, mesmo com amostras pequenas ou desequilibradas.
ic_inf, ic_sup = confint_proportions_2indep( count1=sucessos_h, nobs1=len(h50), count2=sucessos_m, nobs2=len(m50), method='wald'# também pode usar 'score' (mais robusto))print(f"Intervalo de confiança da diferença: [{ic_inf:.2%}, {ic_sup:.2%}]")
Intervalo de confiança da diferença: [2.48%, 37.52%]
Apesar do seu intervalo mudar em relação ao outro método, sua interpretação é a mesma do intervalo com o método wald.
Intervalo de Confiança para a Variância
Exemplo:
Queremos estimar o intervalo para a variância de um grupo. A biblioteca scipy.stats não possui uma função interval específica para variância, porém podemos fazer os cálculos passo a passo.
Variância amostral: 20.25
Intervalo de confiança (95%): [12.84, 36.60]
O intervalo é assimétrico, como é comum em distribuições baseadas no qui-quadrado. Ele mostra que há uma margem considerável de incerteza, ou seja, a variabilidade das idades pode estar moderadamente concentrada ou bastante espalhada, dependendo da população real. Uma análise exploratória responderia essa questão.
Aviso
A variância é uma medida sensível a valores extremos — por isso é natural que o intervalo de confiança reflita isso com uma amplitude maior.
Conclusão
Intervalos de confiança são uma das formas mais práticas e importantes de comunicar incerteza. Em ciência de dados, eles ajudam a entender a precisão das estimativas e tomar decisões com base em evidências — e não em suposições.
Eles aparecem em quase tudo: eleições, testes clínicos, pesquisas de mercado e muito mais. Saber interpretá-los corretamente é uma habilidade fundamental para qualquer analista ou cientista de dados.