import pandas as pd
import altair as alt
import statsmodels.api as sm
from vega_datasets import data
# Carregar e limpar os dados
df = data.cars()
df = df.dropna() # Remove linhas com valores faltantes
df = df.rename(columns={'Miles_per_Gallon': 'mpg', 'Horsepower': 'hp'})
# Verificar se há valores não numéricos e remover se necessário
df = df[pd.to_numeric(df['hp'], errors='coerce').notna()]
df['hp'] = pd.to_numeric(df['hp'])
# Visualizar a relação entre hp e mpg usando Altair
alt.Chart(df).mark_circle(size=60, opacity=0.7).encode(
x=alt.X('hp:Q', title='Potência (hp)'),
y=alt.Y('mpg:Q', title='Eficiência (milhas por galão)'),
color=alt.value('steelblue')
).properties(
title='Eficiência vs Potência dos Carros',
width=600,
height=400
)Regressão Linear Simples e Múltipla
Em Ciência de Dados, é comum nos perguntarmos como uma variável influencia outra. Será que o tamanho de uma casa afeta seu preço? Ou será que a marca de uma roupa influencia seu valor de mercado? Ou será que a potência de um carro está relacionada ao seu consumo de combustível?
Até agora, quando queríamos estudar relações entre variáveis, fazíamos um gráfico de dispersão e verificávamos “no olhômetro” se fazia sentido assumir algum padrão. Mas como colocar esse padrão no papel de forma precisa? Como quantificar exatamente essa relação?
A regressão linear é a ferramenta que nos permite fazer isso. Com ela, conseguimos entender que quando uma variável aumenta um certo tanto, a outra variável tende a aumentar (ou diminuir) um certo tanto também. Mais que isso: conseguimos construir uma equação matemática que captura essa relação e nos permite fazer previsões precisas.
O que é Regressão?
A regressão é uma técnica estatística que nos permite modelar e quantificar a relação entre variáveis. Em essência, estamos procurando a melhor “linha de tendência” que passa pelos nossos dados.
Mas como encontramos essa melhor linha? A resposta está em minimizar os erros de previsão. Queremos a reta que deixe os pontos o mais próximo possível dela. Para isso, utilizamos o método dos mínimos quadrados, que minimiza a soma dos quadrados dos erros (SSE - Sum of Squared Errors).

Na prática, raramente conseguimos explicar 100% da variação dos dados - sempre há fatores que não conseguimos capturar. Mas conseguimos explicar uma boa parte dela e identificar tendências claras!
Regressão Linear Simples
É usada quando temos uma variável explicativa (X) e uma variável resposta (Y). Por exemplo: será que carros com mais potência (X) consomem mais combustível (Y)?
A fórmula básica é:
\[ Y = \beta_0 + \beta_1 X + \varepsilon \]
NotaPor que letras gregas?
Você deve estar se perguntando: “Por que β (beta) ao invés de simplesmente ‘a’ e ‘b’?” É apenas uma convenção da estatística! Poderíamos muito bem escrever:
Y = a + b × X + erro
As letras gregas (β₀, β₁) são tradicionalmente usadas para representar os parâmetros populacionais (valores “verdadeiros” que queremos estimar), enquanto usaríamos letras normais para nossas estimativas. Mas no fundo, é só uma variável como qualquer outra!
Onde:
- β₀: intercepto — valor de Y quando X = 0
- β₁: inclinação — quanto Y muda para cada unidade de aumento em X
- ε: erro aleatório — parcela que o modelo não consegue explicar
Pressupostos da Regressão Linear
Para que os resultados da regressão sejam estatisticamente confiáveis, é importante que alguns pressupostos sejam satisfeitos. Esses pressupostos se aplicam tanto à regressão linear simples quanto à múltipla.
À primeira vista pode parecer muita coisa técnica, mas não se preocupe! Vamos mostrar como verificar cada um deles na prática mais adiante no material.
| Pressuposto | Descrição | Como Verificar |
|---|---|---|
| 1. Linearidade | Relação linear entre variável resposta e explicativas | Gráficos de dispersão ou resíduos vs valores ajustados |
| 2. Independência | Erros independentes entre observações | Teste de Durbin-Watson ou autocorrelação dos resíduos |
| 3. Homocedasticidade | Variância constante dos resíduos | Resíduos vs ajustados (sem padrão cone/funil) |
| 4. Normalidade | Resíduos seguem distribuição normal | Histogramas, QQ-plots, teste de Shapiro-Wilk |
Nem sempre todos os pressupostos estarão perfeitamente atendidos. O importante é avaliar o impacto que isso pode ter sobre as conclusões do modelo, e buscar alternativas quando necessário (como modelos não-lineares ou regressão robusta). A violação de pressupostos não invalida automaticamente o modelo, mas pode afetar a precisão das inferências estatísticas.
Regressão Linear Simples na Prática
Vamos usar o dataset cars do pacote vega_datasets. A variável resposta será Miles_per_Gallon (milhas por galão), e a explicativa será Horsepower (potência).
Podemos observar que, em geral, quanto maior a potência, menor a eficiência (mpg). Ou seja, há uma tendência de queda. Isso faz sentido intuitivo: carros mais potentes conseguem percorrer menos milhas com a mesma quantidade de combustível - eles são menos eficientes. Como dizemos popularmente: são carros que “bebem muito”! 🚗⛽
Vamos dividir a base de dados em duas partes: treino e teste. A parte de treino será usada para ajustar o modelo de regressão simples, enquanto a parte de teste será usada posteriormente na etapa de diagnóstico.
import numpy as np
from sklearn.model_selection import train_test_split
# Reformatar os dados para o sklearn
X = df['hp'].values.reshape(-1, 1) # variável explicativa
y = df['mpg'].values # variável resposta
# Dividir em treino (80%) e teste (20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Vamos usar a função LinearRegression da biblioteca scikit-learn, que ajusta uma função da forma:
\[ mpg = \beta_0 + \beta_1 ⋅ hp\]
from sklearn.linear_model import LinearRegression
# Ajustar o modelo
modelo = LinearRegression()
modelo.fit(X_train, y_train)
# Coeficientes em formato de DataFrame
coeficientes_df = pd.DataFrame({
'Parâmetro': ['Intercepto (β₀)', 'Inclinação (β₁)'],
'Valor': [modelo.intercept_, modelo.coef_[0]],
'Interpretação': [
'Eficiência quando potência = 0',
'Mudança na eficiência por unidade de potência'
]
})
print("Coeficientes do Modelo de Regressão Linear Simples:")
coeficientes_df.round(3)Coeficientes do Modelo de Regressão Linear Simples:| Parâmetro | Valor | Interpretação | |
|---|---|---|---|
| 0 | Intercepto (β₀) | 40.606 | Eficiência quando potência = 0 |
| 1 | Inclinação (β₁) | -0.163 | Mudança na eficiência por unidade de potência |
A partir dos coeficientes estimados, podemos escrever nossa equação de regressão:
Fórmula geral: \[\text{mpg} = \beta_0 + \beta_1 \cdot \text{hp}\]
Substituindo os valores estimados:
\[\text{mpg} = 40.61 - 0.163 \cdot \text{hp}\]
Vamos interpretar esses coeficientes na prática. O intercepto de 40.61 mpg teoricamente representa a eficiência de um carro com 0 cavalos (hp) - o que, convenhamos, não faz muito sentido! 😄 Em algumas situações como essa, o intercepto não possui uma interpretação prática porque sua explicação depende de um valor (0 cavalos) que logicamente não existe na realidade. Nesse caso, simplesmente “esquecemos” o intercepto na interpretação, mas ele ainda é matematicamente útil para o ajuste do modelo.
Uma alternativa seria utilizar uma regressão sem intercepto, que é especialmente útil quando temos situações em que nosso problema possui um truncamento positivo (que não observamos nos dados, mas que logicamente existe) - como no caso dos cavalos de potência, onde sabemos que não existem carros com 0 hp.
O interessante mesmo vem agora: a inclinação de -0.163 milhas por galão por cavalo de potência. Esse valor nos diz que, para cada cavalo de potência adicional, esperamos que o carro percorra 0.16 milhas a menos com a mesma quantidade de combustível (1 galão).
Na prática, isso significa que se compararmos dois carros onde um tem 10 cavalos a mais que o outro, o mais potente conseguirá percorrer cerca de 1.6 milhas a menos com cada galão de combustível (10 × 0.163 ≈ 1.6). É a confirmação matemática do que já sabíamos: potência custa combustível!
Com o modelo ajustado, vamos sobrepor a linha ajustada ao gráfico de dispersão original para entender o que ela representa.
# Previsões no treino e no teste
y_train_pred = modelo.predict(X_train)
y_test_pred = modelo.predict(X_test)
# Criar DataFrame para visualização
train_df = pd.DataFrame({
'hp': X_train.flatten(),
'mpg': y_train,
'mpg_pred': y_train_pred
})
# Pontos de treino
pontos = alt.Chart(train_df).mark_circle(size=60, opacity=0.6, color='steelblue').encode(
x=alt.X('hp:Q', title='Potência (hp)'),
y=alt.Y('mpg:Q', title='Eficiência (mpg)')
)
# Linha de regressão
linha = alt.Chart(train_df).mark_line(color='red', strokeWidth=3).encode(
x=alt.X('hp:Q'),
y=alt.Y('mpg_pred:Q')
)
# Combinar gráficos
(pontos + linha).properties(
title='Regressão Linear: Consumo vs Potência (Dados de Treino)',
width=600,
height=400
)A linha vermelha é a reta de regressão. Ela representa a melhor estimativa do consumo (mpg) para cada valor de potência (hp), segundo o modelo linear. Esta é a linha que minimiza a soma dos quadrados dos erros, como vimos anteriormente.
O R² (coeficiente de determinação) nos diz o quão bem nosso modelo explica a variação dos dados. Vamos calculá-lo e interpretá-lo em termos percentuais:
r2 = modelo.score(X, y)
print(f'Coeficiente de determinação (R²): {r2:.3f}')
print(f'Isso significa que {r2*100:.1f}% da variação no consumo (mpg) é explicada pela potência (hp)')
print(f'Os {(1-r2)*100:.1f}% restantes são devido a outros fatores não incluídos no modelo')Coeficiente de determinação (R²): 0.605
Isso significa que 60.5% da variação no consumo (mpg) é explicada pela potência (hp)
Os 39.5% restantes são devido a outros fatores não incluídos no modeloEm outras palavras, nossa variável potência consegue explicar uma boa parte da variação no consumo dos carros, mas ainda há outros fatores importantes que não estamos considerando (como peso, aerodinâmica, tipo de motor, etc.).
Diagnóstico
Após ajustar o modelo, vamos verificar se os pressupostos estão sendo atendidos. Este é um passo crucial para garantir a validade das nossas conclusões.
Verificação de Linearidade e Homocedasticidade
Faremos o gráfico dos resíduos do modelo versus os valores ajustados. Este gráfico nos ajuda a verificar dois pressupostos importantes simultaneamente:
# Calcular resíduos para todo o dataset
y_pred = modelo.predict(X)
residuos = y - y_pred
# Criar DataFrame para os resíduos
residuos_df = pd.DataFrame({
'valores_ajustados': y_pred,
'residuos': residuos
})
# Gráfico de resíduos vs valores ajustados
pontos_residuos = alt.Chart(residuos_df).mark_circle(size=60, opacity=0.6, color='steelblue').encode(
x=alt.X('valores_ajustados:Q', title='Valores Ajustados'),
y=alt.Y('residuos:Q', title='Resíduos')
)
# Linha horizontal em y=0
linha_zero = alt.Chart(residuos_df).mark_rule(color='red', strokeDash=[5, 5]).encode(
y=alt.datum(0)
)
# Combinar gráficos
(pontos_residuos + linha_zero).properties(
title='Resíduos vs Valores Ajustados - Verificação de Linearidade e Homocedasticidade',
width=600,
height=400
)Como interpretar: Uma ausência de padrão no gráfico sugere linearidade e variância constante. Se os pontos estiverem espalhados aleatoriamente ao redor da linha horizontal em y=0, isso é um bom sinal.
Interpretação do nosso resultado: Podemos observar que existe uma certa tendência em formato de cone no gráfico, o que indica heterocedasticidade (variância não constante). Os resíduos tendem a ser maiores para certos valores ajustados, violando o pressuposto de homocedasticidade.
Verificação de Normalidade dos Resíduos
Vamos usar múltiplas estratégias para verificar se os resíduos seguem distribuição normal:
# Histograma dos resíduos usando Altair
alt.Chart(residuos_df).mark_bar().encode(
x=alt.X('residuos:Q', bin=alt.Bin(maxbins=15), title='Resíduos'),
y=alt.Y('count()', title='Frequência'),
color=alt.value('lightblue'),
stroke=alt.value('black')
).properties(
title='Histograma dos Resíduos - Verificação de Normalidade',
width=500,
height=300
)
Nota📊 Interpretação do Histograma
O histograma nos apresenta um indicativo visual da distribuição dos resíduos. Para normalidade, esperamos ver:
- Formato aproximadamente simétrico (em forma de sino)
- Concentração maior no centro (próximo a zero)
- Diminuição gradual nas extremidades
Porém, o histograma deve ser aliado a outras técnicas mais precisas.
# QQ-plot usando statsmodels (mantém matplotlib por ser ferramenta especializada)
import matplotlib.pyplot as plt
sm.qqplot(residuos, line='45')
plt.title('QQ-plot dos Resíduos - Verificação de Normalidade')
plt.show()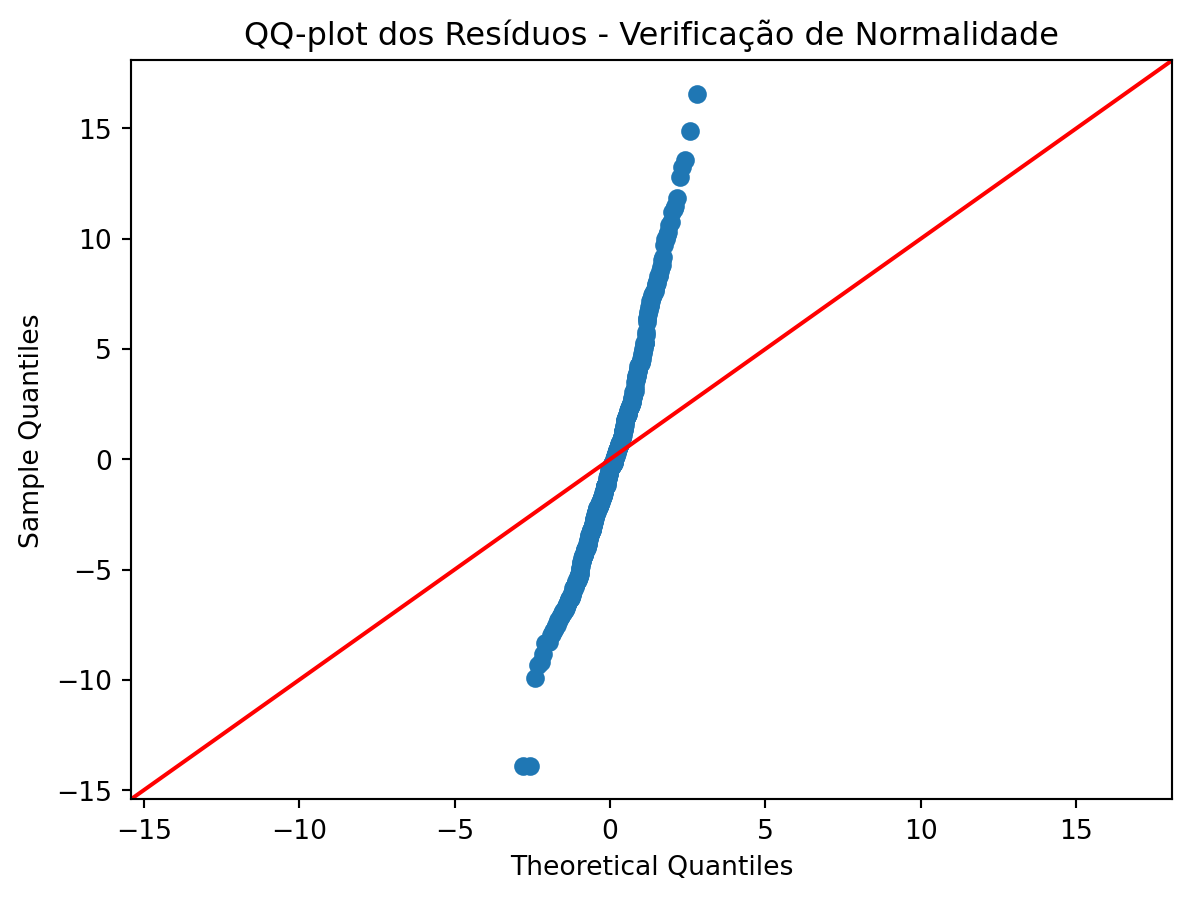
Nota📈 Interpretação do QQ-plot
O Gráfico Quantil-Quantil (QQ-plot) é mais confiável que o histograma para avaliar normalidade:
- Linha vermelha: onde uma distribuição Normal perfeita deveria estar
- Pontos azuis: nossos resíduos observados
- Interpretação: Se os pontos seguem próximos à linha, temos evidência de normalidade. Desvios sistemáticos da linha indicam violação do pressuposto.
Patrões comuns: - Curvatura em “S”: assimetria na distribuição - Pontos se afastam nas extremidades: caudas mais pesadas que a normal
# Teste de Shapiro-Wilk
from scipy.stats import shapiro
estatistica, p_valor = shapiro(residuos)
print(f"Shapiro-Wilk p-valor: {p_valor:.4f}")Shapiro-Wilk p-valor: 0.0002Se o p-valor for maior que 0.05, não rejeitamos a hipótese de normalidade.
📋 Resumo do Diagnóstico de Normalidade:
- Histograma: Distribuição aproximadamente simétrica e em “forma de sino” ✅
- QQ-plot: Pontos se desviam da linha vermelha, especialmente nas extremidades ❌
- Teste de Shapiro-Wilk: p-valor < 0.05, rejeitamos H₀ de normalidade ❌
Conclusão: Pelas três evidências convergentes, os resíduos não seguem distribuição normal. Isso pode afetar:
- Validade dos intervalos de confiança
- Poder dos testes de hipóteses
- Interpretação das significâncias dos coeficientes
A estimação dos coeficientes ainda é válida (método de mínimos quadrados), mas a inferência estatística fica comprometida.
Aviso
Isso pode afetar principalmente a validade dos intervalos de confiança e testes de hipóteses do modelo! Embora a estimação dos coeficientes ainda seja confiavél.
Fazendo Previsões
Agora que temos nosso modelo, vamos usá-lo para fazer uma previsão. Queremos saber quantas milhas por galão um carro com 100 hp de potência consumiria:
# Treinar modelo com todos os dados para previsão
X_simples = df[['hp']]
y = df['mpg']
modelo_simples = LinearRegression().fit(X_simples, y)
# Estimativa com hp = 100
input_simples = pd.DataFrame({'hp': [100]})
estimativa_simples = modelo_simples.predict(input_simples)
print(f"Estimativa (modelo simples) para hp = 100: {estimativa_simples[0]:.2f} mpg")Estimativa (modelo simples) para hp = 100: 24.15 mpgVisualizando a Previsão
Vamos ver essa previsão graficamente, mostrando onde ela se posiciona em relação aos nossos dados:
# Criar dados para visualização da previsão
ponto_previsao = pd.DataFrame({'hp': [100], 'mpg': estimativa_simples})
# Gráfico base com todos os dados
grafico_base = alt.Chart(df).mark_circle(size=60, opacity=0.6, color='lightgray').encode(
x=alt.X('hp:Q', title='Potência (hp)'),
y=alt.Y('mpg:Q', title='Eficiência (mpg)')
)
# Linha de regressão
linha_regressao = alt.Chart(df).transform_regression('hp', 'mpg').mark_line(color='red', strokeWidth=2).encode(
x='hp:Q',
y='mpg:Q'
)
# Ponto da previsão
ponto_destaque = alt.Chart(ponto_previsao).mark_circle(size=200, color='orange', stroke='black', strokeWidth=2).encode(
x=alt.X('hp:Q'),
y=alt.Y('mpg:Q')
)
# Texto da previsão
texto_previsao = alt.Chart(ponto_previsao).mark_text(
align='left', dx=10, dy=-10, fontSize=12, fontWeight='bold', color='darkorange'
).encode(
x='hp:Q',
y='mpg:Q',
text=alt.value(f'Previsão: {estimativa_simples[0]:.1f} mpg')
)
# Combinar todos os elementos
(grafico_base + linha_regressao + ponto_destaque + texto_previsao).properties(
title='Previsão do Modelo: Carro com 100 hp',
width=600,
height=400
)O ponto laranja mostra nossa previsão: um carro com 100 hp de potência teria um consumo estimado baseado na linha de tendência dos nossos dados. Note como a previsão está exatamente sobre a linha de regressão, confirmando que nossa implementação está correta.
Regressão Linear Múltipla
Quando há mais de uma variável explicativa, usamos a forma múltipla. Por exemplo: o consumo de um carro pode depender tanto da sua potência quanto do peso e da aceleração.
A fórmula geral é:
\[ Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \dots + \beta_n X_n + \varepsilon \]
Cada \(\beta_i\) representa o efeito isolado da variável \(X_i\), mantendo as outras constantes.
Importante: Regressões assumem que a relação entre as variáveis é linear e que os erros são distribuídos normalmente com média zero.
Pressupostos
A Regressão Linear Múltipla apresenta os mesmos pressupostos da sua versão Simples, mais um, a ausência de multicolinearidade.
- Ausência de multicolinearidade
As variáveis explicativas do modelo não devem estar fortemente correlacionadas entre si. Isso pode distorcer os coeficientes estimados e dificultar a interpretação.
Como verificar: usar a matriz de correlação ou o VIF (Variance Inflation Factor).
Regressão Linear Múltipla na Prática
Na regressão múltipla, consideramos mais de uma variável explicativa para prever a variável resposta.
Vamos continuar com o consumo de combustível (mpg), mas agora incluindo além da potência (hp), também:
- peso (
Weight_in_lbs): quanto mais pesado o carro, maior o consumo? - aceleração (
Acceleration): carros com melhor aceleração consomem menos?
Nosso modelo agora será:
\[ \text{mpg} = \beta_0 + \beta_1 \cdot \text{hp} + \beta_2 \cdot \text{weight} + \beta_3 \cdot \text{acceleration} + \varepsilon.\]
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# Usar o mesmo dataset já carregado e renomear as colunas para facilitar
df = df.rename(columns={'Weight_in_lbs': 'weight', 'Acceleration': 'acceleration'})
# Verificar e limpar dados
df = df.dropna(subset=['hp', 'weight', 'acceleration', 'mpg'])
df[['hp', 'weight', 'acceleration']] = df[['hp', 'weight', 'acceleration']].apply(pd.to_numeric, errors='coerce')
df = df.dropna()
# Definir variáveis
X = df[['hp', 'weight', 'acceleration']]
y = df['mpg']
# Dividir em treino (80%) e teste (20%)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Ajustar modelo
modelo_multi = LinearRegression()
modelo_multi.fit(X_train, y_train)
# Coeficientes em formato de DataFrame
coef_nomes = ['Intercepto (β₀)'] + [f'{var} (β{i+1})' for i, var in enumerate(X.columns)]
coef_valores = [modelo_multi.intercept_] + list(modelo_multi.coef_)
coef_interpretacoes = [
'Eficiência base do modelo',
'Mudança na eficiência por unidade de potência',
'Mudança na eficiência por libra de peso',
'Mudança na eficiência por unidade de aceleração'
]
coeficientes_multi_df = pd.DataFrame({
'Parâmetro': coef_nomes,
'Valor': coef_valores,
'Interpretação': coef_interpretacoes
})
print("Coeficientes do Modelo de Regressão Linear Múltipla:")
coeficientes_multi_df.round(4)Coeficientes do Modelo de Regressão Linear Múltipla:| Parâmetro | Valor | Interpretação | |
|---|---|---|---|
| 0 | Intercepto (β₀) | 47.1152 | Eficiência base do modelo |
| 1 | hp (β1) | -0.0549 | Mudança na eficiência por unidade de potência |
| 2 | weight (β2) | -0.0058 | Mudança na eficiência por libra de peso |
| 3 | acceleration (β3) | -0.0288 | Mudança na eficiência por unidade de aceleração |
Assim temos o modelo ajustado representado na tabela acima. Podemos escrever a equação completa:
Fórmula geral: \[ \text{mpg} = \beta_0 + \beta_1 \cdot \text{hp} + \beta_2 \cdot \text{weight} + \beta_3 \cdot \text{acceleration}\]
Substituindo os valores estimados:
\[\text{mpg} = 47.12 -0.055 \cdot \text{hp} -0.00580 \cdot \text{weight} -0.029 \cdot \text{acceleration}\]
Vamos interpretar esses coeficientes na prática, lembrando que agora cada efeito é isolado - ou seja, consideramos o impacto de uma variável mantendo todas as outras constantes.
O intercepto de 47.12 milhas por galão teoricamente representa a eficiência de um carro com 0 cavalos, 0 libras de peso e 0 de aceleração - o que novamente não faz sentido prático! Como na regressão simples, “esquecemos” sua interpretação literal, mas ele permanece matematicamente importante para o ajuste.
O interessante vem dos coeficientes das variáveis:
- Potência (-0.055): Para cada cavalo adicional, o carro percorre 0.055 milhas a menos com o mesmo galão, mantendo peso e aceleração fixos
- Peso (-0.0058): Para cada libra adicional de peso, o carro percorre 0.0058 milhas a menos com o mesmo galão, mantendo potência e aceleração fixas
- Aceleração (-0.029): Para cada unidade adicional de aceleração, o carro percorre 0.029 milhas a menos com o mesmo galão, mantendo potência e peso fixos
Por exemplo, se compararmos dois carros onde um tem 20 cavalos a mais, 500 libras a mais e 2 unidades de aceleração a mais, esperaríamos que o “pior” percorra aproximadamente 4 milhas a menos por galão: (20 × 0.055) + (500 × 0.0058) + (2 × 0.029) = 1.1 + 2.9 + 0.058 ≈ 4 milhas.
from sklearn.metrics import r2_score
# Previsões
y_train_pred = modelo_multi.predict(X_train)
y_test_pred = modelo_multi.predict(X_test)
# Avaliação
r2_train = r2_score(y_train, y_train_pred)
r2_test = r2_score(y_test, y_test_pred)
print(f"\nR² (Treino): {r2_train:.2f}")
print(f"R² (Teste): {r2_test:.2f}")
R² (Treino): 0.72
R² (Teste): 0.65O R² nos mostra que o modelo múltiplo explica uma porcentagem maior da variação do que o modelo simples. Vamos interpretá-lo em termos percentuais:
print(f'O modelo múltiplo explica {r2_train*100:.1f}% da variação no consumo (mpg)')
print(f'Os {(1-r2_train)*100:.1f}% restantes são devido a outros fatores não incluídos')O modelo múltiplo explica 71.5% da variação no consumo (mpg)
Os 28.5% restantes são devido a outros fatores não incluídosIsso representa uma melhoria significativa em relação ao modelo simples! Incluir mais variáveis nos permite capturar mais da complexidade real do mundo.
Diagnóstico do Modelo Múltiplo
O diagnóstico do modelo múltiplo segue os mesmos princípios do modelo simples, mas com uma verificação adicional importante: a multicolinearidade.
Verificação de Multicolinearidade
Para modelos múltiplos, precisamos verificar se as variáveis explicativas estão muito correlacionadas entre si. Usaremos o VIF (Fator de Inflação de Variância), que mede diretamente o impacto da multicolinearidade na variância dos coeficientes.
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif_df = pd.DataFrame()
vif_df["Variável"] = X.columns
vif_df["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print("\nFatores de Inflação da Variância (VIF):")
print(vif_df)
Fatores de Inflação da Variância (VIF):
Variável VIF
0 hp 40.625093
1 weight 63.889908
2 acceleration 8.961498🔍 Interpretação dos valores de VIF:
- VIF ≤ 5: Correlação baixa a moderada (aceitável)
- 5 < VIF ≤ 10: Correlação elevada (atenção necessária)
- VIF > 10: Multicolinearidade crítica (problema sério)
📊 Análise dos nossos resultados: O resultado mostra multicolinearidade severa no conjunto de preditores. Isso não compromete a capacidade preditiva do modelo (as previsões podem continuar boas), mas causa problemas na interpretação:
⚠️ Consequências da multicolinearidade:
- Instabilidade: Coeficientes sensíveis a pequenas mudanças nos dados
- Interpretação: Difícil isolar o impacto individual de cada variável
- Significância: Erros-padrão inflados podem mascarar variáveis relevantes
- Confiabilidade: Intervalos de confiança mais amplos
💡 Soluções possíveis: Remoção de variáveis correlacionadas, PCA, ou técnicas de regularização (Ridge/Lasso).
Verificação de Homocedasticidade
import numpy as np
# Calcular resíduos do conjunto de teste
residuos_teste = y_test - y_test_pred
# Criar DataFrame para visualização
residuos_teste_df = pd.DataFrame({
'valores_previstos': y_test_pred,
'residuos_abs': np.abs(residuos_teste)
})
# Gráfico de homocedasticidade
alt.Chart(residuos_teste_df).mark_circle(size=60, opacity=0.6, color='steelblue').encode(
x=alt.X('valores_previstos:Q', title='Valores Previstos'),
y=alt.Y('residuos_abs:Q', title='|Resíduos|')
).properties(
title='Verificação de Homocedasticidade - Modelo Múltiplo',
width=600,
height=400
)Verificação de Normalidade dos Resíduos
from scipy.stats import shapiro
# Teste
stat, p_value = shapiro(residuos_teste)
print("\nTeste de Shapiro-Wilk (normalidade dos resíduos):")
print(f"Estatística = {stat:.4f}, p-valor = {p_value:.4f}")
if p_value > 0.05:
print("→ Não rejeitamos H₀: resíduos seguem distribuição normal.")
else:
print("→ Rejeitamos H₀: resíduos não seguem distribuição normal.")
Teste de Shapiro-Wilk (normalidade dos resíduos):
Estatística = 0.9597, p-valor = 0.0138
→ Rejeitamos H₀: resíduos não seguem distribuição normal.# QQ-plot usando statsmodels (ferramenta especializada para diagnóstico)
import matplotlib.pyplot as plt
sm.qqplot(residuos_teste, line='45')
plt.title('QQ-plot dos Resíduos - Modelo Múltipla')
plt.show()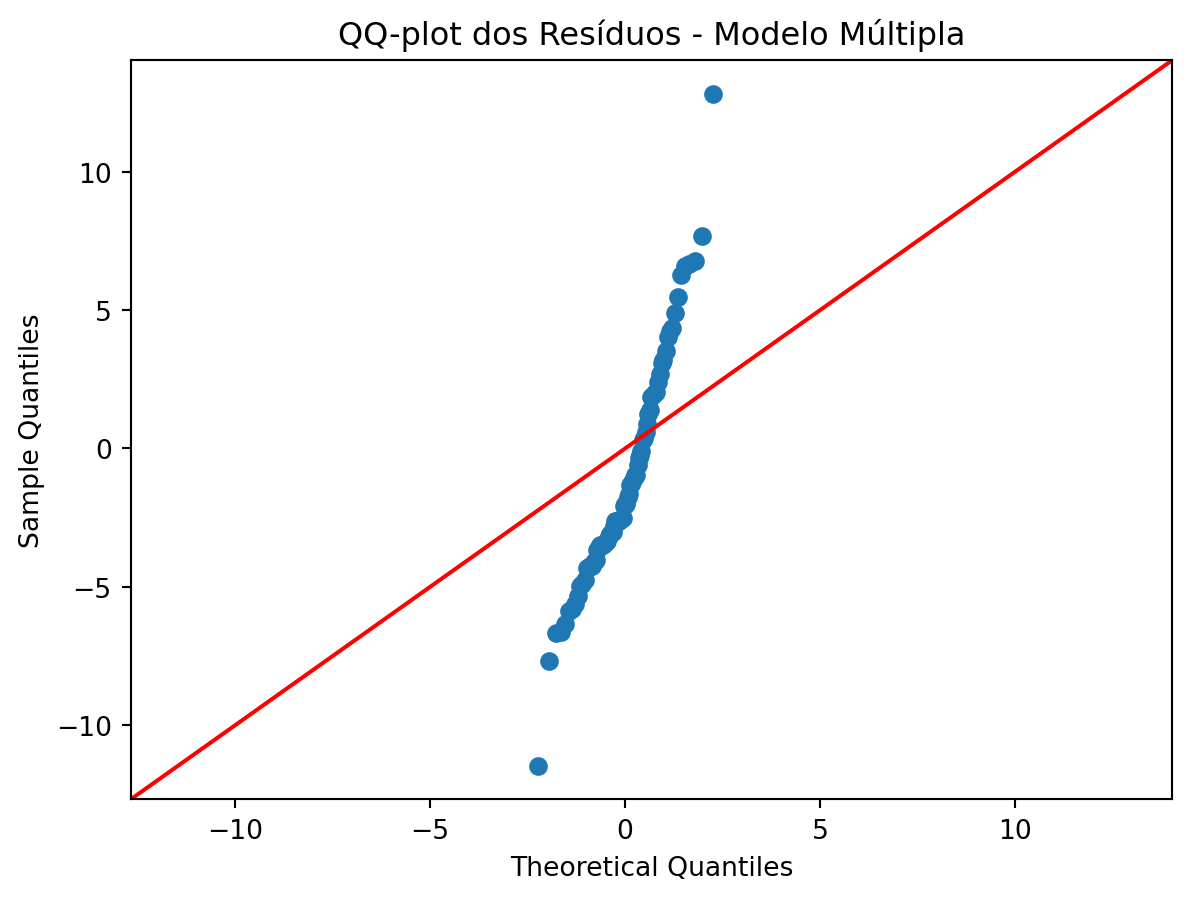
Fazendo Previsões com o Modelo Múltiplo
Para o modelo múltiplo, precisamos fornecer valores para todas as variáveis explicativas. Vamos fazer uma previsão para um carro com características específicas:
X_multi = df[['hp', 'weight', 'acceleration']]
modelo_multiplo = LinearRegression().fit(X_multi, y)
# Valores para previsão
entrada = pd.DataFrame({
'hp': [100],
'weight': [2800],
'acceleration': [15.5]
})
estimativa_multipla = modelo_multiplo.predict(entrada)
print(f"Estimativa (modelo múltiplo) para hp = 100, weight = 2800, acceleration = 15.5: {estimativa_multipla[0]:.2f} mpg")Estimativa (modelo múltiplo) para hp = 100, weight = 2800, acceleration = 15.5: 24.69 mpg🔄 Comparação: Modelo Simples vs Múltipla
Para o mesmo exemplo (carro com 100 hp), vamos comparar as estimativas dos dois modelos:
# Calcular métricas de comparação
r2_simples = modelo_simples.score(df[['hp']], df['mpg'])
r2_multiplo = modelo_multiplo.score(df[['hp', 'weight', 'acceleration']], df['mpg'])
# Criar DataFrame de comparação
comparacao_df = pd.DataFrame({
'Métrica': [
'Previsão para carro exemplo (mpg)',
'R² (coeficiente de determinação)',
'R² em percentual',
'Variância explicada',
'Melhoria no ajuste'
],
'Modelo Simples': [
f"{estimativa_simples[0]:.2f}",
f"{r2_simples:.3f}",
f"{r2_simples*100:.1f}%",
f"{r2_simples*100:.1f}% da variação explicada",
"Baseline"
],
'Modelo Múltiplo': [
f"{estimativa_multipla[0]:.2f}",
f"{r2_multiplo:.3f}",
f"{r2_multiplo*100:.1f}%",
f"{r2_multiplo*100:.1f}% da variação explicada",
f"+{((r2_multiplo-r2_simples)*100):.1f} pontos percentuais"
]
})
print("📊 COMPARAÇÃO DOS MODELOS:")
comparacao_df📊 COMPARAÇÃO DOS MODELOS:| Métrica | Modelo Simples | Modelo Múltiplo | |
|---|---|---|---|
| 0 | Previsão para carro exemplo (mpg) | 24.15 | 24.69 |
| 1 | R² (coeficiente de determinação) | 0.606 | 0.706 |
| 2 | R² em percentual | 60.6% | 70.6% |
| 3 | Variância explicada | 60.6% da variação explicada | 70.6% da variação explicada |
| 4 | Melhoria no ajuste | Baseline | +10.0 pontos percentuais |
🎯 Principais diferenças:
| Aspecto | Modelo Simples | Modelo Múltiplo |
|---|---|---|
| Variáveis | Apenas hp |
hp + weight + acceleration |
| Complexidade | Baixa (mais interpretável) | Maior (mais difícil de interpretar) |
| Poder explicativo | Limitado (apenas 1 fator) | Maior (considera múltiplos fatores) |
| Pressupostos | 4 pressupostos básicos | 5 pressupostos (+ multicolinearidade) |
| Aplicação | Análises exploratórias iniciais | Modelagem mais realista |
💡 Quando usar cada um:
- Simples: Exploração inicial, relações claras, interpretabilidade prioritária
- Múltiplo: Modelagem realista, alta precisão, múltiplos fatores relevantes
Conclusão
A regressão linear é uma ferramenta fundamental para quantificar relações entre variáveis, transformando observações visuais em afirmações matemáticas precisas. Pode ser aplicada em diferentes contextos, desde análise de consumo de combustível até previsões econômicas, sempre fornecendo insights valiosos para a tomada de decisão.
Os principais pontos que vimos foram: - Regressão encontra a melhor linha através dos dados usando mínimos quadrados - O diagnóstico de pressupostos é crucial para garantir a validade dos resultados - Modelos múltiplos capturam mais complexidade, mas exigem cuidado com multicolinearidade - A interpretação deve focar no significado prático dos coeficientes
Com essa base, você está pronto para aplicar regressão linear em seus próprios projetos de ciência de dados!
Recursos Adicionais
- Livros:
- Introduction to Statistical Learning (James et al.) - Capítulos 3 e 6
- Hands-On Machine Learning with Scikit-Learn and TensorFlow (Aurélien Géron) - Capítulo 4
- The Elements of Statistical Learning (Hastie et al.) - Capítulo 3
- Documentação:
- Tutoriais Online: