# Imports necessários
import numpy as np
import pandas as pd
import altair as alt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# Carregar dataset Palmer Penguins
penguins = pd.read_csv('https://raw.githubusercontent.com/allisonhorst/palmerpenguins/master/inst/extdata/penguins.csv')
penguins = penguins.dropna()Redução de Dimensionalidade com PCA
Já se perguntou como podemos visualizar dados com muitas características ao mesmo tempo? Ou como identificar quais variáveis são realmente importantes em um dataset complexo?
O PCA (Principal Component Analysis) é uma técnica que nos ajuda a simplificar dados complexos, mantendo as informações mais importantes. Desenvolvida há mais de um século, continua sendo uma das ferramentas mais úteis para análise exploratória de dados.
Nesta aula, vamos aprender como o PCA pode revelar padrões ocultos nos dados dos pinguins de Palmer, mostrando como diferentes características se relacionam entre si.
O Algoritmo PCA
O PCA funciona de forma intuitiva: ele encontra as direções onde os dados variam mais. Imagine que você está olhando uma nuvem de pontos de cima - o PCA encontra os melhores ângulos para observar essa nuvem, capturando o máximo de informação possível.
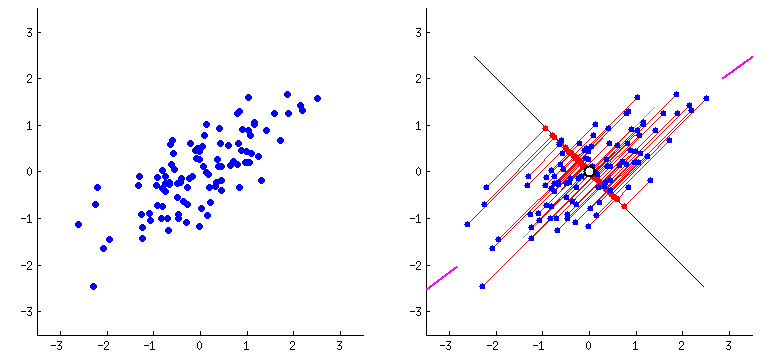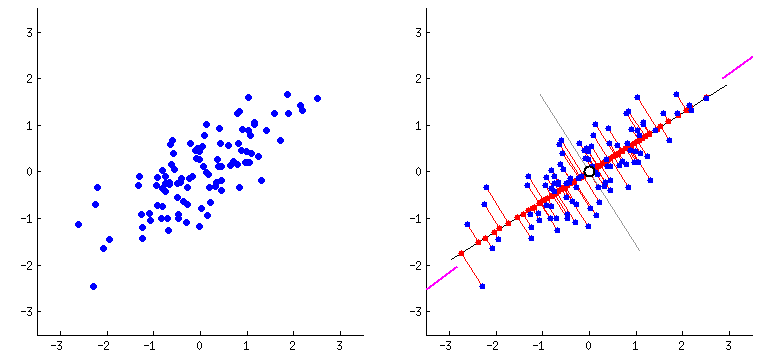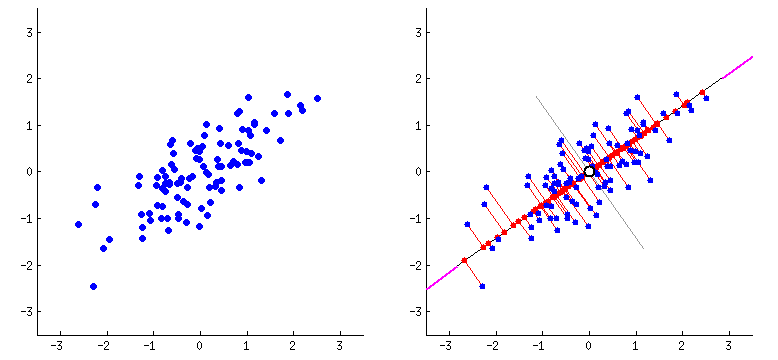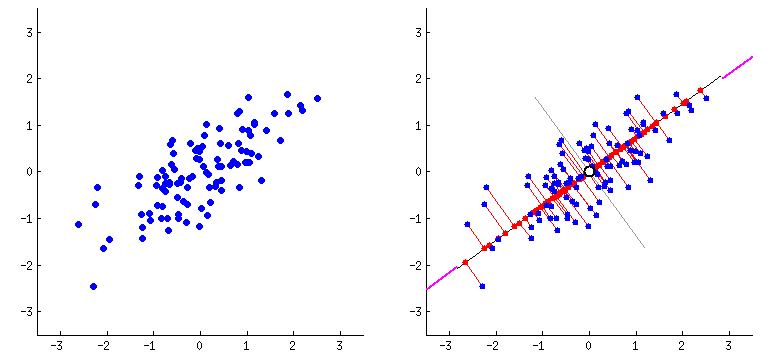
Na animação acima, vemos como o PCA identifica a primeira direção principal (linha preta maior) onde os dados têm maior variação, e depois a segunda direção (linha preta menor) perpendicular à primeira. Essas direções se tornam nossos componentes principais.
No exemplo da animação temos 2 variáveis e obtemos 2 componentes principais. Mas poderíamos ter 100 variáveis e o PCA geraria 100 componentes! A vantagem é que não precisamos usar todos - podemos filtrar e utilizar apenas os primeiros componentes que tenham a maior variabilidade.
Por variabilidade, entendemos o quanto aquele componente consegue explicar as diferenças que observamos nos dados. Se estamos estudando pinguins, por exemplo, os primeiros componentes principais capturam as características que mais distinguem uma espécie da outra, ou que melhor explicam as variações físicas entre os indivíduos. Assim, ao invés de analisar 100 variáveis, podemos focar apenas nos 2 ou 3 componentes mais importantes que conseguem explicar 90% ou 95% de toda a variação do problema!
Aplicando PCA nos Pinguins de Palmer
Vamos ver o PCA em ação com os dados dos pinguins. Utilizaremos o scikit-learn (sklearn), a biblioteca padrão para machine learning em Python, que oferece uma implementação eficiente e bem documentada do algoritmo PCA.
Para aplicar o PCA, usaremos apenas as variáveis numéricas que descrevem as características físicas dos pinguins. Utilizaremos novamente o scikit-learn para implementar o algoritmo PCA de forma eficiente. A padronização dos dados é fundamental porque o PCA é sensível à escala das variáveis - se uma variável tem valores muito maiores que outras (como peso em gramas vs comprimento em milímetros), ela dominará os cálculos e distorcerá os resultados.
# Usar apenas variáveis numéricas para PCA
X_penguins = penguins[['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']].values
# Padronizar os dados (importante para PCA)
scaler = StandardScaler()
X_penguins_scaled = scaler.fit_transform(X_penguins)
# Aplicar PCA
pca_penguins = PCA(n_components=4)
X_pca_penguins = pca_penguins.fit_transform(X_penguins_scaled)Antes de interpretar os resultados, precisamos entender quanto da variância original cada componente principal consegue explicar. Esta análise é fundamental para decidir quantos componentes usar na prática - não adianta fixarmos arbitrariamente 2 ou 3 componentes sem verificar se eles retêm informação suficiente dos dados originais. Vamos examinar a variância explicada:
# Calcular variância explicada
var_explicada = pca_penguins.explained_variance_ratio_
var_acumulada = np.cumsum(var_explicada)
# Gráfico de variância explicada
var_df = pd.DataFrame({
'Componente': ['PC1', 'PC2', 'PC3', 'PC4'],
'Variância_Individual': var_explicada,
'Variância_Acumulada': var_acumulada
})
# Gráfico de barras (variância individual)
bar_chart = alt.Chart(var_df).mark_bar(color='skyblue').encode(
x=alt.X('Componente:O', title='Componente Principal'),
y=alt.Y('Variância_Individual:Q', title='Proporção da Variância')
)
# Linha acumulada
line_chart = alt.Chart(var_df).mark_line(point=True, color='red', strokeWidth=2).encode(
x=alt.X('Componente:O'),
y=alt.Y('Variância_Acumulada:Q')
)
# Combinar gráficos
(bar_chart + line_chart).properties(
title='Variância Explicada por Componente',
width=500,
height=300
)Vemos que PC1 e PC2 juntos capturam a maior parte da informação! Por isso, podemos usar apenas esses 2 componentes ao invés das 4 variáveis originais. Agora vamos comparar os dados originais com os transformados:
# Comparar dados originais vs transformados
penguins_pca = penguins.copy()
penguins_pca['PC1'] = X_pca_penguins[:, 0]
penguins_pca['PC2'] = X_pca_penguins[:, 1]
# Dados originais
original_chart = alt.Chart(penguins).mark_circle(size=80, opacity=0.7).encode(
x=alt.X('bill_length_mm:Q', title='Comprimento do Bico (mm)'),
y=alt.Y('bill_depth_mm:Q', title='Profundidade do Bico (mm)'),
color=alt.Color('species:N', scale=alt.Scale(scheme='category10'), title='Espécie')
).properties(
title='Dados Originais (Mostrando apenas duas variáveis)',
width=350,
height=300
)
# Dados transformados pelo PCA
pca_chart = alt.Chart(penguins_pca).mark_circle(size=80, opacity=0.7).encode(
x=alt.X('PC1:Q', title=f'PC1 ({var_explicada[0]:.1%} da variância)'),
y=alt.Y('PC2:Q', title=f'PC2 ({var_explicada[1]:.1%} da variância)'),
color=alt.Color('species:N', scale=alt.Scale(scheme='category10'), title='Espécie')
).properties(
title='Dados Transformados (PCA)',
width=350,
height=300
)
original_chart | pca_chartA diferença é impressionante! No gráfico à esquerda, as espécies Adelie e Chinstrap se misturam bastante. Já no gráfico à direita, o PCA conseguiu separar as três espécies de forma muito mais clara. Os dois primeiros componentes capturam 88,1% da informação original, transformando quatro variáveis em apenas duas dimensões mais informativas.
Interpretando os Resultados
Uma das grandes vantagens do PCA é que ele não é uma caixa preta - podemos entender exatamente como cada componente principal foi construído a partir das variáveis originais.
Vamos examinar a composição dos componentes principais. A tabela abaixo mostra quanto cada variável original contribui para formar cada componente principal. Valores próximos de zero indicam pouca influência, enquanto valores altos (positivos ou negativos) mostram forte contribuição:
# Criar DataFrame com as contribuições das variáveis
feature_names = ['bill_length_mm', 'bill_depth_mm', 'flipper_length_mm', 'body_mass_g']
components_df = pd.DataFrame(
pca_penguins.components_[:2].T, # Transpor para ter variáveis nas linhas
columns=['PC1', 'PC2'],
index=feature_names
)
components_df.round(3)| PC1 | PC2 | |
|---|---|---|
| bill_length_mm | 0.454 | 0.600 |
| bill_depth_mm | -0.399 | 0.796 |
| flipper_length_mm | 0.577 | 0.006 |
| body_mass_g | 0.550 | 0.076 |
Agora vamos visualizar essas contribuições graficamente através de um biplot, que combina os dados transformados com vetores mostrando como cada variável original se projeta no novo espaço:
# Visualizar as contribuições como vetores (biplot)
fig_biplot = alt.Chart(penguins_pca).mark_circle(size=60, opacity=0.6).encode(
x=alt.X('PC1:Q', title=f'PC1 ({var_explicada[0]:.1%} da variância)'),
y=alt.Y('PC2:Q', title=f'PC2 ({var_explicada[1]:.1%} da variância)'),
color=alt.Color('species:N',
scale=alt.Scale(scheme='category10'),
title='Espécie',
legend=alt.Legend(
orient='top-left',
direction='horizontal',
titleAnchor='start'
))
).properties(
width=680,
height=350
)
# Criar dados para os vetores (loadings)
loadings_data = []
for i, feature in enumerate(feature_names):
loadings_data.append({
'feature': feature,
'PC1': pca_penguins.components_[0, i] * 2, # Escalar para visualização
'PC2': pca_penguins.components_[1, i] * 2,
'PC1_end': 0,
'PC2_end': 0
})
loadings_df = pd.DataFrame(loadings_data)
# Vetores das variáveis (linhas)
vectors = alt.Chart(loadings_df).mark_rule(color='red', strokeWidth=2).encode(
x=alt.X('PC1_end:Q'),
y=alt.Y('PC2_end:Q'),
x2=alt.X2('PC1:Q'),
y2=alt.Y2('PC2:Q')
)
# Pontas das flechas
arrows = alt.Chart(loadings_df).mark_point(
shape='triangle-right',
color='red',
size=100,
filled=True
).encode(
x=alt.X('PC1:Q'),
y=alt.Y('PC2:Q'),
angle=alt.Angle('angle:Q')
).transform_calculate(
angle='atan2(datum.PC2, datum.PC1) * 180 / PI'
)
# Labels dos vetores
labels = alt.Chart(loadings_df).mark_text(
align='left',
baseline='middle',
dx=5,
dy=5,
fontSize=12,
fontWeight='bold',
color='red'
).encode(
x=alt.X('PC1:Q'),
y=alt.Y('PC2:Q'),
text=alt.Text('feature:N')
)
# Combinar todos os elementos
(fig_biplot + vectors + arrows + labels).resolve_scale(
color='independent'
)PC1 (68,8% da variância) é dominado por características de tamanho corporal:
- Valores positivos altos para
flipper_length_mm(0.577),body_mass_g(0.550) ebill_length_mm(0.454) - Valor negativo para
bill_depth_mm(-0.399) - Interpretação: PC1 separa pinguins grandes (valores positivos) de pinguins pequenos (valores negativos). Pinguins maiores tendem a ter nadadeiras mais longas, maior massa corporal, bicos mais compridos, mas curiosamente bicos menos profundos.
PC2 (19,3% da variância) foca nas características específicas do bico:
- Valores altos para
bill_depth_mm(0.796) ebill_length_mm(0.600) - Valores baixos para características corporais (
flipper_length_mm: 0.006,body_mass_g: 0.076) - Interpretação: PC2 distingue pinguins pela forma do bico, independentemente do tamanho corporal. Valores positivos indicam bicos mais longos e profundos.
No biplot acima, os vetores vermelhos mostram como cada variável original se projeta no espaço PC1-PC2. Vetores longos indicam variáveis que contribuem mais para a variação, e vetores na mesma direção indicam variáveis correlacionadas positivamente.
Conclusão
A redução de dimensionalidade com PCA é uma ferramenta fundamental para explorar e visualizar dados complexos de forma eficiente. Através dos dados dos pinguins de Palmer, pudemos observar como o PCA consegue condensar informações de múltiplas variáveis em componentes principais que preservam a essência dos dados originais.
O algoritmo demonstrou sua capacidade de revelar padrões ocultos nos dados, melhorando significativamente a separação entre as espécies quando comparado às variáveis originais. Além disso, sua natureza interpretável permite compreender exatamente quais características físicas mais contribuem para distinguir os diferentes grupos de pinguins.
O PCA encontra aplicação em diversos contextos da ciência de dados, desde análise exploratória até pré-processamento para outros algoritmos de machine learning, sempre fornecendo insights valiosos sobre a estrutura subjacente dos dados e facilitando a tomada de decisão baseada em evidências quantitativas.
Recursos Adicionais
- Hands-On Machine Learning with Scikit-Learn and TensorFlow (Aurélien Géron)
- Principal Component Analysis Explained
- PCA Explained (IBM)