Introdução à Ciência de Dados
A Ciência de Dados está cada vez mais presente em nossas vidas, mesmo que muitas vezes de forma invisível. Quando você recebe recomendações de filmes e séries em uma plataforma de streaming, quando seu banco detecta uma transação suspeita ou quando autoridades de saúde monitoram a propagação de doenças — tudo isso envolve a aplicação de técnicas de Ciência de Dados.
Neste módulo introdutório, vamos entender o que é Ciência de Dados, como ela funciona na prática, que ferramentas são utilizadas e quais os desafios éticos associados. A ideia é construir uma base sólida para que você possa compreender projetos da área e, eventualmente, conduzir os seus próprios.
O que é Ciência de Dados?
A Ciência de Dados é uma disciplina que combina habilidades de estatística, programação, engenharia e conhecimento de domínio para extrair conhecimento a partir de dados. Ela busca não apenas entender fenômenos observados, mas também fazer previsões, automatizar processos e embasar decisões com evidências quantitativas.
Ela pode ser entendida como a interseção de três áreas principais:
- Matemática e Estatística (base analítica);
- Ciência da Computação (base tecnológica);
- Conhecimento de Domínio (contexto específico do problema).
O profissional de dados — cientista, analista ou engenheiro — atua conectando essas três dimensões para resolver problemas reais.
Áreas envolvidas na prática
Cada projeto de dados pode exigir um conjunto diferente de habilidades, mas algumas áreas aparecem com frequência:
- Estatística e probabilidade: base para inferência, modelagem e interpretação dos dados.
- Programação (em R ou Python): necessária para manipulação de dados, construção de algoritmos e automação de análises.
- Engenharia de dados: envolve capturar, armazenar, transformar e disponibilizar dados para análise.
- Visualização de dados: traduz informações complexas em gráficos e dashboards acessíveis.
- Ética e governança de dados: fundamental para garantir uso justo, transparente e responsável dos dados.
Exemplos
Operação Serenata de Amor
A Operação Serenata de Amor é um projeto brasileiro de fiscalização cidadã que mostra como dados abertos e inteligência artificial podem ser usados para o bem público. Ele analisa reembolsos de parlamentares brasileiros com algoritmos de auditoria automática.
Um dos principais componentes técnicos do projeto é a Rosie, uma robô desenvolvida em Python que automatiza a análise de notas fiscais associadas à cota parlamentar. A Rosie avalia dados como valores, datas, categorias de despesa e localizações geográficas para identificar possíveis irregularidades. Cada suspeita levantada é publicada em uma base pública de dados, promovendo a transparência e permitindo que cidadãos, jornalistas e órgãos de controle possam acompanhar e investigar os casos.
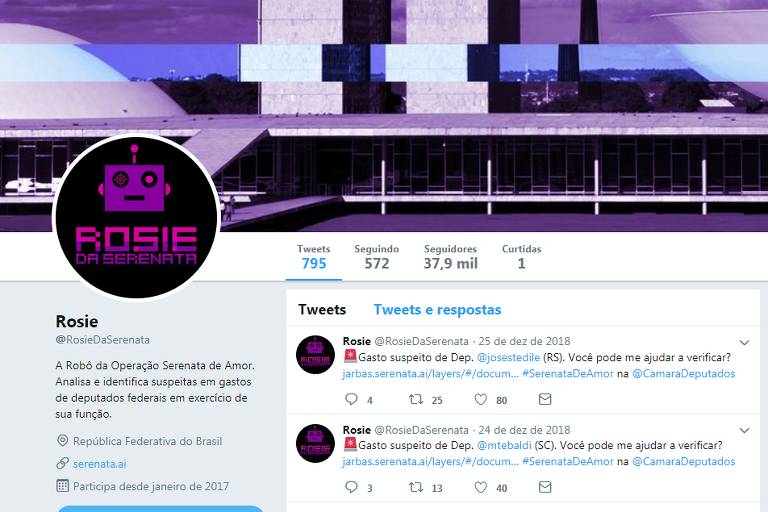
Com base em dados públicos da Câmara dos Deputados, o sistema consegue detectar inconsistências como almoços em datas incompatíveis ou gastos duplicados. As descobertas são reportadas de forma clara nas redes sociais e estimulam o engajamento cívico. Esse exemplo reforça que a Ciência de Dados não se limita ao setor privado — ela também é uma ferramenta de transformação social.
Acesse o site oficial da Operação Serenata de Amor
Leia a reportagem do G1 sobre a Operação Serenata de Amor
Assista ao vídeo sobre a Operação Serenata de Amor no YouTube
Esportes Profisionais
Um dos casos mais famosos do uso da Ciência de Dados no esporte é retratado no filme Moneyball: O Homem que Mudou o Jogo. Baseado em uma história real, o filme mostra como o gerente do time de beisebol Oakland Athletics, Billy Beane, revolucionou o recrutamento de jogadores usando análise estatística avançada em vez de avaliações subjetivas de olheiros.

Em vez de buscar jogadores caros e com “talento visível”, Beane e o economista Peter Brand (inspirado no analista Paul DePodesta) desenvolveram modelos estatísticos que identificavam jogadores subvalorizados, mas com alto desempenho em métricas específicas — como a taxa de chegada em base (OBP). O resultado foi uma das temporadas mais eficientes da história da Major League Baseball em termos de custo-benefício.
Assista à essa cena do filme Moneyball
A adoção dessas técnicas resultou em 20 vitórias consecutivas e mudou a forma como times em diversos esportes estruturam seus elencos:
- Objeção ao método tradicional de olheiros (scouting);
- Uso de dados reais para tomadas de decisão;
- Expansão para basquete, futebol e outras modalidades.
Hoje, praticamente todos os grandes clubes e franquias esportivas no mundo usam análise de dados para recrutamento, preparo físico, estratégias táticas e até prevenção de lesões.
Saúde Pública
A aplicação de ciência de dados e inteligência artificial (IA) na saúde pública tem transformado a forma como o SUS identifica demandas, aloca recursos e previne doenças. Por meio da análise de grandes volumes de dados — como registros hospitalares, notificações de doenças e campanhas de vacinação — é possível prever surtos, otimizar o uso de leitos e apoiar decisões clínicas.
Assista o vídeo do Dr. Drauzio Varela sobre IA na saúde pública
Um exemplo prático é o uso de modelos preditivos no monitoramento da dengue, permitindo ações antecipadas em regiões de risco. Iniciativas como o DATASUS, o Painel de Monitoramento da Saúde Digital e o uso de IA em hospitais públicos vêm mostrando como tecnologia e saúde pública podem andar juntas.
Outros
Educação
Nos Estados Unidos, o estado de Montana desenvolveu um sistema de alerta precoce baseado em dados escolares para identificar alunos com risco de evasão. O modelo utiliza notas, frequência e comportamento para acionar intervenções nas escolas.
Agronegócio
Sensores em plantações e dados climáticos têm sido integrados em sistemas que ajudam produtores a decidir o momento ideal de irrigação, colheita e aplicação de fertilizantes. Uma aplicação prática disso está descrita neste artigo que explora o uso de Big Data no agronegócio.
Ferramentas Comuns
Na prática, cientistas de dados trabalham com diversas ferramentas que auxiliam na análise, visualização e compartilhamento dos resultados:
- Linguagens: Python (pandas, scikit-learn, seaborn, matplotlib, altair,…);
- Ambientes: Jupyter Notebooks, RStudio, VSCode;
- Dashboards e visualizações: Power BI, Shiny, Plotly, Tableau;
- Versionamento: Git e GitHub, fundamentais para colaboração e controle de versões;
- Armazenamento e consulta: SQL, BigQuery, MongoDB.
Nessas oficinas usaremos a linguagem Python!
Etapas de um Projeto de Ciência de Dados
Cada projeto pode ter especificidades, mas costuma seguir um fluxo comum:
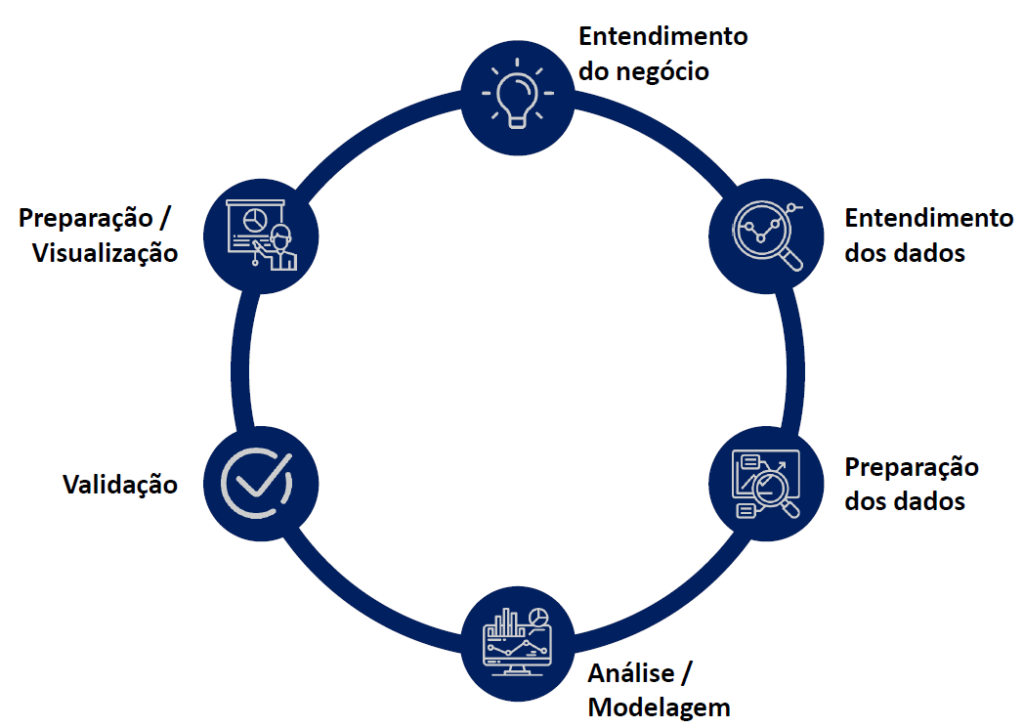
Entendimento do problema: reunião com stakeholders (as pessoas envolvidas no projeto, e/ou aqueles que irão se beneficiar com a solução) para compreender os objetivos.
Coleta de dados: acesso a bases internas, APIs públicas, dados de censos, etc. Nessa etapa, é fundamental entender quais os tipos de dados irão pautar o projeto, pois o tipo de coleta dos dados e o tipo do dado em si, vão ditar o que pode ser feito com ele.
Preparação dos dados: exclusão de valores nulos, padronização de formatos, criação de variáveis.Já coletamos os dados mas precisamos tratá-los antes de começar nossas análises.
- O tratamento dos dados será abordado no Módulo 2: Análise Exploratória de Dados.
- Análise exploratória (AED): visualização de dados, identificação de padrões, correlações e outliers. Nessa fase, se intensifica a necessidade de habilidades com ferramentas analíticas para pensar em ideias e hipóteses a serem validadas.
- Análise explorátoria de dados será apresentada no Módulo 2: Análise Exploratória de Dados.
- Modelagem: seleção e aplicação de algoritmos preditivos ou descritivos. Essa etapa necessita de ainda mais repertório de análise ainda mais complexo.
- Tópicos de Modelagem serão vistos inicialmente no Módulo 3: Inferência Estatística e, com mais profundidade, no Módulo 4: Modelagem Estatística.
- Validação e avaliação: comparação de métricas como acurácia, F1-score ou RMSE. Aqui vamos medir o desempenho e a eficácia dos modelo usados anteriormente.
- Métodos de validação e avaliação estão presentes no Módulo 4: Modelagem Estatística
- Apresentação de resultados: criação de relatórios, painéis e apresentações. Finalmente, após esse longo processo o sucesso do projeto será apresentado!
Ética e Responsabilidade
Com grandes volumes de dados e algoritmos potentes, surgem também grandes responsabilidades. Questões como privacidade, transparência e vieses precisam estar no centro das decisões.
- Privacidade: cuidado com dados pessoais e sensíveis;
- Consentimento: uso responsável das informações fornecidas por indivíduos;
- Vieses algorítmicos: sistemas de recomendação e predição podem reproduzir discriminações históricas se não forem cuidadosamente ajustados;
- Transparência e explicabilidade: especialmente em modelos complexos (como redes neurais), é essencial buscar formas de explicar decisões automáticas.
A ética em Ciência de Dados é um campo em expansão e essencial para garantir que seus usos estejam alinhados com valores democráticos e sociais.
Veja esse artigo sovbre a Lei Geral de Proteção de Dados Pessoais (LGPD)
Conclusão
Parabéns! Você adentrou no fascinante mundo da Ciência de Dados e já viu onde as técnicas que vamos apresentar estão presentes na sua vida e onde podem ser incorporadas para lhe ajudar no dia a dia. Essa introdução servirá de base para os próximos assuntos da nossa Oficina.