A Análise de Variância, conhecida como ANOVA, é uma técnica estatística que permite comparar a média de três ou mais grupos ao mesmo tempo. Ela é uma extensão do teste t, que foi apresentado na seção de Testes de Hipótese, e responde à pergunta:
“Existe alguma diferença significativa entre as médias desses grupos?”
Esta guia complementa a seção sobre testes de hipótese, aprofundando a ANOVA com explicações, pressupostos, interpretação e exemplos em Python.
Nota
Quando temos dois grupos, a ANOVA é equivalente ao teste T.
Quando usar ANOVA?
Use ANOVA quando:
Você deseja comparar três ou mais grupos independentes;
Os dados são numéricos e contínuos;
Cada grupo foi formado por amostragem aleatória;
Você quer saber se pelo menos um grupo tem média diferente dos outros.
Pressupostos da ANOVA
Antes de aplicar a ANOVA, é necessário verificar se os dados atendem aos seguintes pressupostos:
Independência das observações (os dados dos grupos não estão relacionados);
Normalidade dentro de cada grupo (distribuição aproximadamente normal);
Homogeneidade das variâncias (os grupos têm variâncias semelhantes).
Esses pressupostos podem ser verificados com testes como Shapiro-Wilk (normalidade) e Levene (homogeneidade de variâncias), como já foi apresentado anteriormente.
Exemplo prático em Python
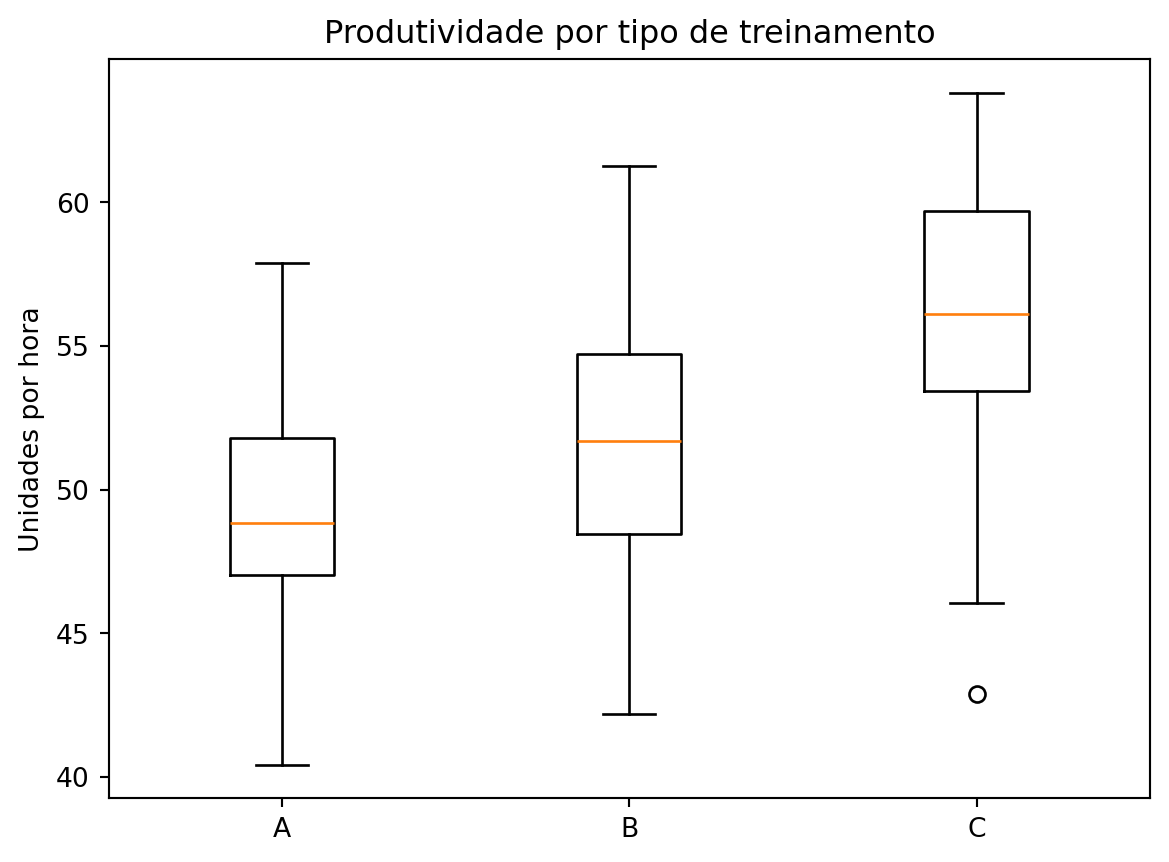
Vamos supor que queremos comparar a produtividade (em unidades por hora) de trabalhadores sob três grupo que tiveram tipos diferentes de treinamento.
import numpy as npfrom scipy.stats import f_onewayimport matplotlib.pyplot as pltnp.random.seed(42)# Simulação de três grupos com médias diferentesgrupo_a = np.random.normal(loc=50, scale=5, size=30)grupo_b = np.random.normal(loc=52, scale=5, size=30)grupo_c = np.random.normal(loc=56, scale=5, size=30)# Visualizaçãoplt.boxplot([grupo_a, grupo_b, grupo_c], tick_labels=['A', 'B', 'C'])plt.title("Produtividade por tipo de treinamento")plt.ylabel("Unidades por hora")plt.show()# ANOVAstat, p = f_oneway(grupo_a, grupo_b, grupo_c)print(f'Estatística F: {stat:.2f}, p-valor: {p:.4f}')
Estatística F: 17.21, p-valor: 0.0000
Interpretação do Resultado
O gráfico de boxplot compara a produtividade (em unidades por hora) entre três grupos diferentes (A, B e C), cada um representando um tipo de treinamento. A diferença nas medianas (linha central das caixas) sugere que os grupos podem ter níveis médios de produtividade diferentes. Isso é ainda mais reforçado pelo distanciamento entre as caixas, principalmente entre os grupos A e C.
Já para a ANOVA, analisamos o p-valor:
Se o p-valor < 0.05, rejeitamos a hipótese nula e concluímos que pelo menos um grupo é diferente;
Se o p-valor ≥ 0.05, não há evidência suficiente de que as médias diferem.
Como vemos, o p-valor é < que 0.05, portanto, pelo menos um dos três grupos do exemplo é diferente em sua média de produtivida de. A ANOVA diz se existe diferença, mas não diz entre quais grupos. Para isso, usamos testes post hoc, como o Tukey HSD.
Teste Post Hoc: Tukey HSD
O Teste de Tukey, também conhecido como Teste de Diferença Honestamente Significativa de Tukey (HSD), é um teste post hoc usado após uma análise de variância (ANOVA) para identificar quais grupos específicos têm médias significativamente diferentes dos outros. Ele compara todos os pares possíveis de grupos e mostra quais grupos são realmente diferentes entre si.
Corrigindo o teste de Tukey
Quando comparamos muitos pares de grupos ao mesmo tempo, há mais chance de encontrar uma diferença que na verdade não existe. O pacote statsmodels aplica uma correção automática: ela ajusta os p-valores automaticamente para evitar falsos positivos, ou seja, evita detectar diferenças que não existem ao comparar vários pares. Essa correção serve para deixar a análise mais confiável, mesmo quando estamos testando várias comparações ao mesmo tempo.
import pandas as pdfrom statsmodels.stats.multicomp import pairwise_tukeyhsd# Reorganizando os dados em um DataFrameprodutividade = np.concatenate([grupo_a, grupo_b, grupo_c])grupos = ['A'] *30+ ['B'] *30+ ['C'] *30df = pd.DataFrame({'produtividade': produtividade, 'grupo': grupos})# Teste de Tukeyresultado_tukey = pairwise_tukeyhsd(endog=df['produtividade'], groups=df['grupo'], alpha=0.05)#print(resultado_tukey)
A tabela abaixo resume os resultados obtidos pela função:
Grupo 1
Grupo 2
Diferença
p-valor ajustado
Limite inferior
Limite superior
Decisão
A
B
2.3349
0.139
-0.5643
5.2341
Não
A
C
7.0052
0.0
4.106
9.9044
Sim
B
C
4.6702
0.0007
1.771
7.5694
Sim
Grupo A vs Grupo B: Não há diferença estatisticamente significativa, pois o p-valor é maior que 0.05 e o intervalo inclui zero.
Grupo A vs Grupo C: Há uma diferença significativa, com o Grupo C apresentando valores médios mais altos.
Grupo B vs Grupo C: Também há uma diferença significativa, novamente favorecendo o Grupo C.
Assim, podemos dizer que o treinamento dos Grupos A e B são os únicos que apresentam médias de produtividades iguais.
Correção Bonferroni
Agora vamos repetir o teste, mas aplicando a correção de Bonferroni, que é mais conservadora. Aqui, estamos usando a função allpairtest para fazer todos os pares de testes T corrigidos com a correção de Bonferroni.
from statsmodels.stats.multicomp import MultiComparisonfrom scipy.stats import ttest_indmc = MultiComparison(df['produtividade'], df['grupo'])# Aplica t-test para todos os pares com correção Bonferroniresultado_bonf = mc.allpairtest(ttest_ind, method='bonf')#print(resultado_bonf[0])
A tabela abaixo resume os resultados obtidos pela função:
Grupo 1
Grupo 2
Estatística
p-valor
p-valor ajustado
Diferença significativa?
A
B
-1.9752
0.053
0.159
Não
A
C
-5.7292
0.0000
0.0000
Sim
B
C
-3.7604
0.0004
0.0012
Sim
O Bonferroni é mais rigoroso e pode confirmar os mesmos resultados que o Tukey ou rejeitar diferenças mais sutis. Nesse caso, obtivemos os mesmos resultados do teste de Tukey.
ANOVA com um Fator
Às vezes os dados vêm organizados em uma tabela com uma variável categórica indicando o grupo, e uma variável numérica com a medida. Neste caso, podemos usar uma abordagem mais estruturada com o pacote statsmodels para rodar a ANOVA e extrair a tabela de análise completa. Usaremos os mesmos dados do exemplo anterior:
import statsmodels.api as smimport statsmodels.formula.api as smf# Dados já organizados como antesdf = pd.DataFrame({'produtividade': produtividade, 'grupo': grupos})# Modelo de ANOVA com fórmulamodelo = smf.ols('produtividade ~ grupo', data=df).fit()tabela_anova = sm.stats.anova_lm(modelo, typ=2)#print(tabela_anova)
O print da tabela adaptado:
Fonte de Variação
Soma dos Quadrados (SQ)
Graus de Liberdade (df)
Estatística F
p-valor (PR(>F))
Grupo
763.35
2
17.21
5.03 × 10⁻⁷
Residual (Erro)
1929.22
87
—
—
Aqui, da mesma forma, avaliamos o p-valor do teste, 5.03 × 10⁻⁷ é tão pequeno que pode ser considerado 0, portanto concluímos denovo que pelo menos um dos 3 grupos é diferente.
ANOVA de dois fatores
Quando você tem mais de um fator categórico influenciando uma variável numérica, você entra no território da ANOVA de dois fatores (ou two-way ANOVA).
Exemplo
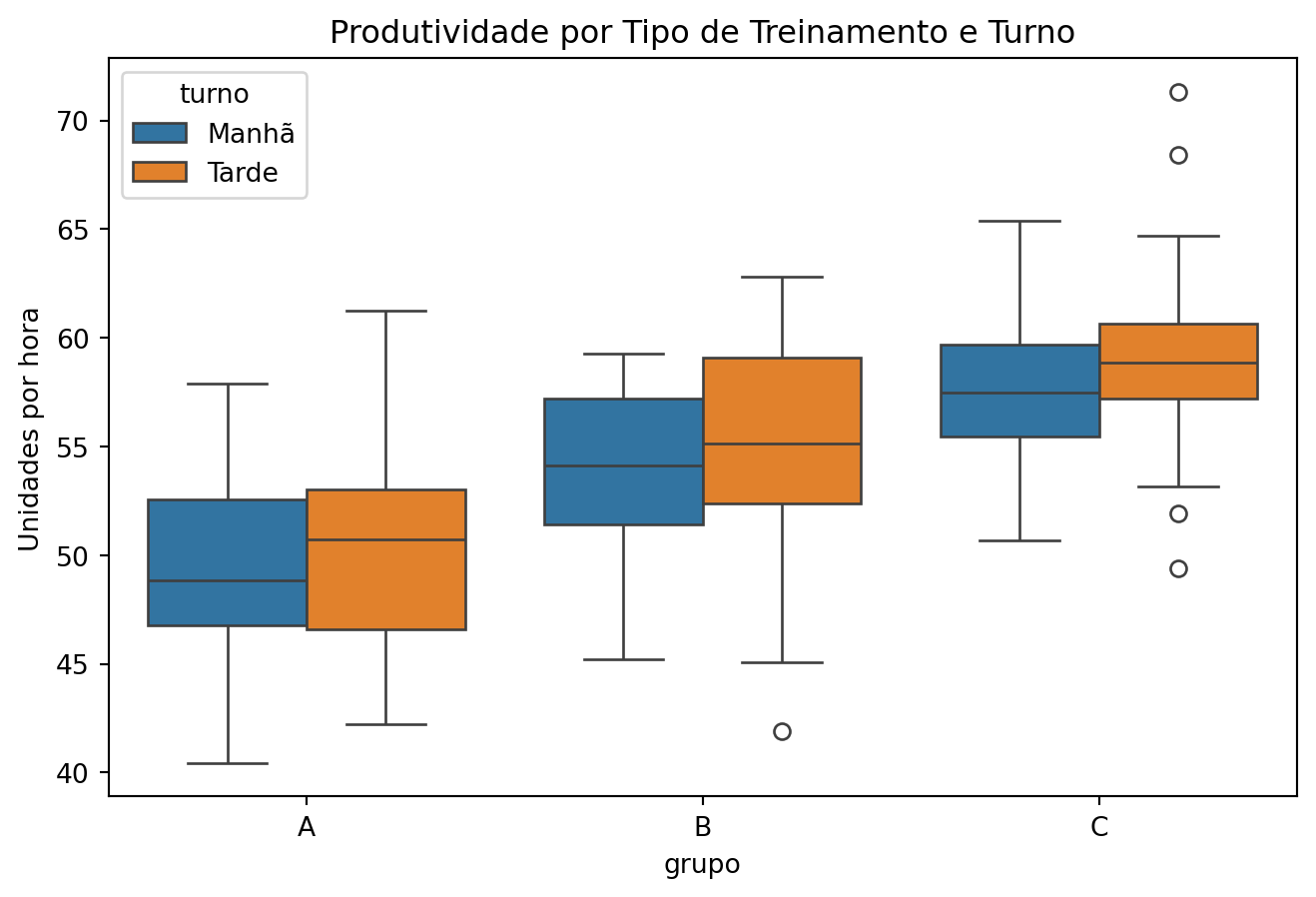
Vamos expandir o exemplo da produtividade dos grupos por tipo de treinamento (A, B, C) acrescentando um segundo fator: o turno de trabalho (Manhã ou Tarde).
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.api as smfrom statsmodels.formula.api import olsimport seaborn as snsnp.random.seed(42)# Simulando produtividade por grupo e turnon =20grupo = ['A', 'B', 'C']turno = ['Manhã', 'Tarde']dados = []for g in grupo:for t in turno:if g =='A': media =50if t =='Manhã'else52elif g =='B': media =54if t =='Manhã'else55else: media =58if t =='Manhã'else59 produtividade = np.random.normal(loc=media, scale=5, size=n)for p in produtividade: dados.append({'produtividade': p, 'grupo': g, 'turno': t})df = pd.DataFrame(dados)# Visualizaçãoplt.figure(figsize=(8,5))sns.boxplot(x='grupo', y='produtividade', hue='turno', data=df)plt.title('Produtividade por Tipo de Treinamento e Turno')plt.ylabel('Unidades por hora')plt.show()
O gráfico mostra que:
Os grupos B e C tendem a ter maior produtividade do que o grupo A.
A diferença entre manhã e tarde não parece muito grande visualmente dentro de cada grupo.
As caixas dos grupos B e C (principalmente) estão deslocadas para valores maiores em comparação ao grupo A.
O tipo de treinamento tem forte influência na produtividade, como já tínhamos visto.
O turno não tem efeito significativo na produtividade média.
Não há interação significativa entre os dois fatores, ou seja, o efeito do grupo é consistente nos dois turnos — o grupo C sempre vai melhor que B e A, independentemente do turno.
Considerações finais
A ANOVA é uma ferramenta poderosa e amplamente usada quando temos mais de dois grupos para comparar. Ela evita o erro de múltiplas comparações que ocorreria se fizéssemos vários testes t separados. Se usada corretamente — com os pressupostos verificados, fornece uma análise estatística robusta sobre diferenças entre grupos.
Conclusão do Módulo Três
Se você chegou até aqui, parabéns! Você acaba de concluir um dos blocos mais importantes da análise de dados. Agora, você sabe como usar intervalos de confiança para estimar valores com base em amostras, aplicar testes de hipótese para comparar grupos de forma estruturada e utilizar a ANOVA para investigar diferenças entre mais de duas médias.
Com esse conhecimento, você está preparado para tomar decisões baseadas em evidências, identificar padrões com mais segurança e evitar conclusões precipitadas.