Em Ciência de Dados, muitas vezes queremos saber se uma diferença observada em nossos dados é real ou se pode ter acontecido apenas por sorte. Imagine, por exemplo, que você quer saber se uma nova campanha de marketing realmente aumentou as vendas, ou se um novo método de ensino melhorou as notas de alunos. Como responder a essas perguntas de forma confiável? A resposta está nos testes de hipóteses.
Esses testes nos ajudam a tomar decisões baseadas em dados, e não apenas em suposições. Eles funcionam como uma ferramenta que avalia se os resultados observados são convincentes o suficiente para considerar que algo realmente mudou ou aconteceu de forma diferente.
Neste guia, vamos explorar dois tipos principais de testes — os paramétricos e os não paramétricos — e entender quando cada um é mais apropriado, sempre com exemplos simples e diretos.
Objetivos
Compreender o conceito de testes de hipóteses e seu papel em análises estatísticas.
Distinguir testes paramétricos de não paramétricos.
Aplicar testes com exemplos práticos.
Utilizar bibliotecas do Python para execução e interpretação dos testes.
Conceito
Um teste de hipóteses é um procedimento estatístico para “verificar se algo” de maneira confiável. Imagine que temos dois grupos — um que usou um método antigo e outro que usou um novo. Se as médias forem diferentes, será que isso foi por causa do novo método ou por acaso?
O teste de hipótese vai calcular a chance de essa diferença ter acontecido por sorte. Se essa chance for muito pequena, dizemos que é uma diferença significativa, ou seja, muito provavelmente real.
Envolve duas hipóteses:
Hipótese nula (H₀): suposição padrão, geralmente de que “não há diferença” ou “nada mudou”.
Hipótese alternativa (H₁): suposição contrária à hipótese nula, geralmente a que queremos provar, como “há uma diferença” ou “o novo remédio é melhor”.
Importante
A decisão é feita com base em um nível de significância (α), normalmente 0,05 (5%). Se o valor-p (p-value) calculado for menor que α, rejeitamos H₀.
Aviso
Cada teste possui pressupostos que precisam ser atendidos antes de ser feito, se esses pressupostos não forem atendidos os resultados do teste podem ser enganosos.
Testes
Testes Paramétricos
Você pode pensar nos testes paramétricos como aqueles que funcionam melhor quando os dados estão “organizados”, ou seja, seguem um padrão mais previsível. Eles são ideais quando:
Os dados têm uma forma parecida com uma curva em sino (como altura ou peso);
As medições são contínuas (ex: notas, salários, tempo).
Assumem que os dados seguem uma distribuição específica, normalmente a distribuição normal. São mais potentes quando os pressupostos são atendidos.
Exemplos:
Teste t de Student (comparação de médias)
ANOVA (análise de variância)
Correlação de Pearson
Exemplo prático:
Queremos saber se duas turmas diferentes (Turma A e Turma B) têm, em média, pesos diferentes. Coletamos uma amostra aleatória de pesos de alunos de cada turma. Para fazer o teste de médias vamos usar o teste T:
Hipótese nula (H₀): há evidência de diferença significativa entre as médias dos pesos.
Hipótese alternativa (H₁): não há evidência de diferença significativa entre as médias dos pesos.
Nota
Para fazer esse teste vamos assumir que os dados seguem a distribuição normal e ambos os grupos tem variâncias parecidas
from scipy.stats import ttest_indimport numpy as np# Simulando pesos com distribuição normalnp.random.seed(42)turma_a = np.random.normal(loc=25, scale=3, size=20)turma_b = np.random.normal(loc=27, scale=3, size=20)stat, p = ttest_ind(turma_a, turma_b)print(f'Teste t para duas médias: estatística = {stat:.2f}, p-valor = {p:.4f}')# Interpretaçãoif p <0.05:print("Rejeitamos H0: há evidência de diferença significativa entre as médias.")else:print("Não rejeitamos H0: não há evidência de diferença significativa.")
Teste t para duas médias: estatística = -1.88, p-valor = 0.0683
Não rejeitamos H0: não há evidência de diferença significativa.
Testes Não Paramétricos
São mais robustos, pois não exigem que os dados sigam distribuições específicas e úteis quando os dados são ordinais, assimétricos ou têm variância desigual.
Exemplos:
Teste de Mann-Whitney (alternativa ao t-test)
Teste de Wilcoxon (para dados pareados)
Teste de Kruskal-Wallis (alternativa à ANOVA)
Correlação de Spearman
Exemplo prático:
Vamos continuar com o nosso exemplo anterior das Turmas A e B, mas agora vamos usar o teste de Mann-Whitney que é a alternativa não-paramética para o teste t e tem as mesmas hipóteses do teste T.
from scipy.stats import mannwhitneyuimport numpy as np# Simulando pesosnp.random.seed(42)turma_a = np.random.normal(loc=25, scale=3, size=20)turma_b = np.random.normal(loc=27, scale=3, size=20)stat, p = mannwhitneyu(turma_a, turma_b, alternative='two-sided')print(f'Teste de Mann-Whitney: estatística = {stat:.2f}, p-valor = {p:.4f}')# Interpretaçãoif p <0.05:print("Rejeitamos H0: há diferença significativa entre os grupos.")else:print("Não rejeitamos H0: não há evidência de diferença significativa.")
Teste de Mann-Whitney: estatística = 138.00, p-valor = 0.0962
Não rejeitamos H0: não há evidência de diferença significativa.
Ambos os testes indicam que não há uma diferença significativa entre os pesos das duas turmas.
Dica
Use o teste t quando as idades forem aproximadamente normais e com variâncias parecidas.
Use o teste de Mann-Whitney quando os dados forem assimétricos, com outliers ou não atenderem os pressupostos do teste t.
Pressupostos
Como já foi dito, cada teste possui pressupostos. Abaixo estão os pressupostos mais comuns para os testes e como verificar se seus dados os atendem.
1. Normalidade
Este é o pressuposto mais importante para testes paramétricos como o t de Student e a ANOVA. Ele indica se os dados seguem uma distribuição em forma de sino, como a distribuição normal.
Como verificar:
Visualmente:
Histograma: deve apresentar simetria.
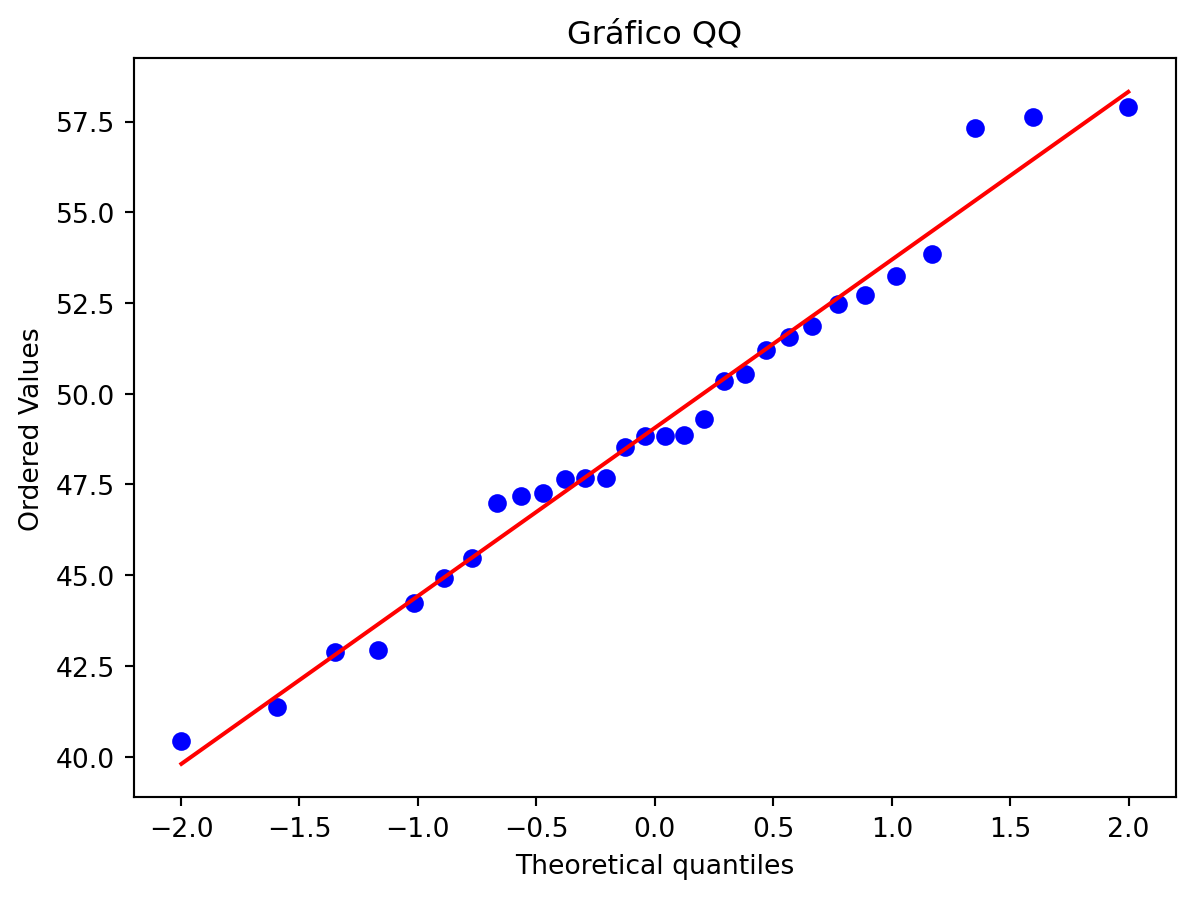
Gráfico QQ (Quantil-Quantil): os pontos devem seguir aproximadamente uma linha reta.
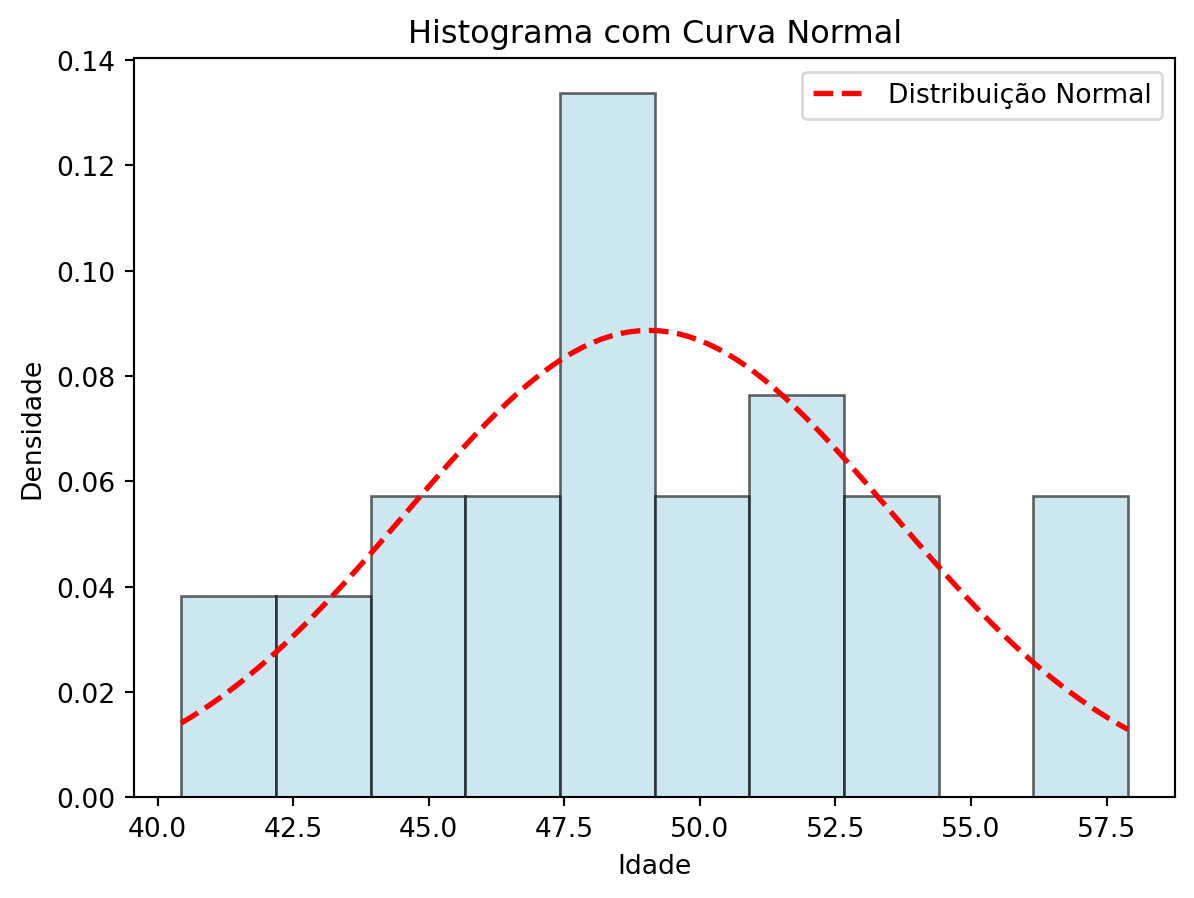
Para ilustrar o pressuposto de normalidade, podemos usar uma variável dados com distribuição normal, como já temos feito em nossos exemplos com idades.
import numpy as npimport matplotlib.pyplot as pltfrom scipy.stats import norm, probplot# Gerando os dados simuladosnp.random.seed(42)dados = np.random.normal(loc=50, scale=5, size=30)# Informações da amostramedia = np.mean(dados)desvio_padrao = np.std(dados, ddof=1)# Criar o histograma normalizadocount, bins, ignored = plt.hist(dados, bins=10, density=True, alpha=0.6, edgecolor='black', color='lightblue')# Plotar a curva normal teóricax = np.linspace(min(bins), max(bins), 100)plt.plot(x, norm.pdf(x, media, desvio_padrao), 'r--', linewidth=2, label='Distribuição Normal')# Estética do gráficoplt.title('Histograma com Curva Normal')plt.xlabel('Idade')plt.ylabel('Densidade')plt.legend()plt.show()# Gráfico QQprobplot(dados, dist='norm', plot=plt)plt.title('Gráfico QQ')plt.show()
O histograma mostra como os valores de idade estão distribuídos. Neste caso, temos um formato de sino, típico de uma distribuição normal, com a maioria das idades próximas da média (50 anos).
O gráfico QQ compara a distribuição dos dados com uma distribuição normal teórica. Os pontos alinhados sobre a linha diagonal indicam que os dados seguem razoavelmente uma distribuição normal. Desvios fortes da linha indicariam que a distribuição dos dados é diferente da normal.
Testes estatísticos:
Shapiro-Wilk (ideal para amostras pequenas)
D’Agostino-Pearson (melhor para amostras maiores)
from scipy.stats import shapiro, normalteststat, p = shapiro(dados)print(f'Teste de Shapiro-Wilk: estatística = {stat:.2f}, p-valor = {p:.4f}')stat, p = normaltest(dados)print(f'Teste de D’Agostino-Pearson: estatística = {stat:.2f}, p-valor = {p:.4f}')
Teste de Shapiro-Wilk: estatística = 0.98, p-valor = 0.6868
Teste de D’Agostino-Pearson: estatística = 0.15, p-valor = 0.9260
Ambos os testes verificam se os dados se comportam como uma distribuição normal. O p-valor indica se temos evidências para desconfiar disso:
Se o valor for muito pequeno (ex: menor que 0,05), os dados provavelmente não seguem uma distribuição normal.
Se o valor for grande o bastante(ex: maior que 0,05), não há indícios fortes de que a distribuição seja diferente da normal.
Nesse exemplo, ambos os p-valores são bem maiores que 0,05 o que indica que os dados seguem a distribuição Normal.
2. Homogeneidade de variância
É importante nos testes paramétricos que os grupos tenham variâncias semelhantes.
Como verificar:
Teste de Levene ou teste de Bartlett:
from scipy.stats import leveneimport numpy as npnp.random.seed(42)grupo1 = np.random.normal(loc=50, scale=10, size=30)grupo2 = np.random.normal(loc=55, scale=5, size=30)stat, p = levene(grupo1, grupo2)print(f'Teste de Levene: estatística = {stat:.2f}, p-valor = {p:.4f}')
Teste de Levene: estatística = 7.47, p-valor = 0.0083
Se p > 0.05, as variâncias podem ser consideradas iguais. Como aqui temos um valor bem menor, consideramos as variâncias diferentes.
3. Independência entre as observações
Cada dado deve representar uma observação independente. Esse pressuposto depende do desenho do estudo:
Certifique-se de que os grupos comparados não compartilham os mesmos participantes ou registros.
Evite usar dados repetidos sem métodos apropriados para análise pareada.
4. Tipo e escala dos dados
Testes paramétricos: dados numéricos contínuos.
Testes não paramétricos: funcionam com dados ordinais ou quando os pressupostos acima não são atendidos.
Com esses cuidados, a aplicação dos testes se torna mais precisa, e as conclusões — mais confiáveis.
Lista de Testes
Abaixo estão os testes mais comuns usados em análises de dados, com explicações simples sobre o que eles verificam e como utilizá-los no Python.
Testes t de Student
O que verifica:
Compara se a média de um grupo é igual a um valor específico.
Compara as médias de dois grupos diferentes.
Compara a proporção de um grupo é igual a um valor específico.
Compara as proporções de dois grupos diferentes.
Usado quando: os dados são numéricos e têm distribuição parecida com uma curva em sino.
Pressupostos: dados com distribuição normal, variâncias semelhantes e observações independentes.
Função:scipy.stats.ttest_ind(a, b) para grupos independentes ou ttest_rel(a, b) para dados pareados.
Comparando uma média
Verifica: se a média de um grupo é diferente de um valor conhecido.
Hipóteses:
H₀: a média do grupo é igual ao valor de referência.
H₁: a média do grupo é diferente do valor de referência.
Função:ttest_1samp(grupo, popmean=x).
from scipy.stats import ttest_1sampnp.random.seed(42)grupo = np.random.normal(loc=102, scale=4, size=30)stat, p = ttest_1samp(grupo, popmean=100)print(f'Estatística: {stat:.2f}, p-valor: {p:.4f}')
Estatística: 1.90, p-valor: 0.0677
Comparando duas médias (amostras independentes)
Verifica: se a média de dois grupos diferentes é significativamente distinta.
Hipóteses:
H₀: as médias dos dois grupos são iguais.
H₁: as médias dos dois grupos são diferentes.
Função:ttest_ind(grupo1, grupo2).
from scipy.stats import ttest_indimport numpy as npnp.random.seed(42)grupo1 = np.random.normal(loc=50, scale=5, size=30)grupo2 = np.random.normal(loc=55, scale=5, size=30)stat, p = ttest_ind(grupo1, grupo2)print(f'Teste t para duas médias: estatística = {stat:.2f}, p-valor = {p:.4f}')
Teste t para duas médias: estatística = -4.51, p-valor = 0.0000
Comparando uma proporção
Verifica: se a proporção observada difere de uma proporção esperada.
Hipóteses:
H₀: a proporção do grupo é igual à proporção esperada.
import statsmodels.api as sm# Exemplo: proporções de pessoas com 50+ anossucessos = [35, 23] # Homens e Mulherestotais = [60, 60]stat, p = sm.stats.proportions_ztest(sucessos, totais)print(f'Diferença de proporções: estatística = {stat:.2f}, p-valor = {p:.4f}')
Diferença de proporções: estatística = 2.19, p-valor = 0.0284
ANOVA (Análise de Variância)
Verifica: se há diferença entre três ou mais grupos.
Hipóteses:
H₀: todas as médias dos grupos são iguais.
H₁: pelo menos uma das médias dos grupos é diferente.
Pressupostos: normalidade dos dados, variâncias semelhantes entre os grupos e independência entre as observações.
Verifica: se duas variáveis numéricas estão relacionadas linearmente.
Hipóteses:
H₀: não existe correlação linear entre as duas variáveis.
H₁: existe correlação linear entre as duas variáveis.
Pressupostos: relação linear, dados contínuos, normalidade e ausência de outliers extremos.
Função:scipy.stats.pearsonr(x, y).
from scipy.stats import pearsonrnp.random.seed(42)x = np.random.normal(loc=50, scale=5, size=30)y = x + np.random.normal(loc=0, scale=2, size=30)corr, p = pearsonr(x, y)print(f'Correlação: {corr:.2f}, p-valor: {p:.4f}')
Correlação de Spearman
Verifica: se duas variáveis estão relacionadas de forma geral (não necessariamente linear).
Hipóteses:
H₀: não existe correlação entre os postos das duas variáveis.
H₁: existe correlação entre os postos das duas variáveis.
Pressupostos: dados ordinais ou contínuos, sem necessidade de normalidade.
Função:scipy.stats.spearmanr(x, y).
from scipy.stats import spearmanrnp.random.seed(42)x = np.random.uniform(0, 100, size=30)y = np.sqrt(x) + np.random.normal(0, 1, size=30)corr, p = spearmanr(x, y)print(f'Correlação de Spearman: {corr:.2f}, p-valor: {p:.4f}')
Quando usar cada tipo?
Com tantos testes é fácil ficar confuso e não saber da cara qual usar para resolver seu problema. No geral:
Use testes paramétricos quando os dados forem contínuos, simétricos e com distribuição aproximadamente normal.
Use testes não paramétricos quando os dados forem assimétricos, categóricos ordinais, ou quando os pressupostos dos testes paramétricos não forem atendidos.
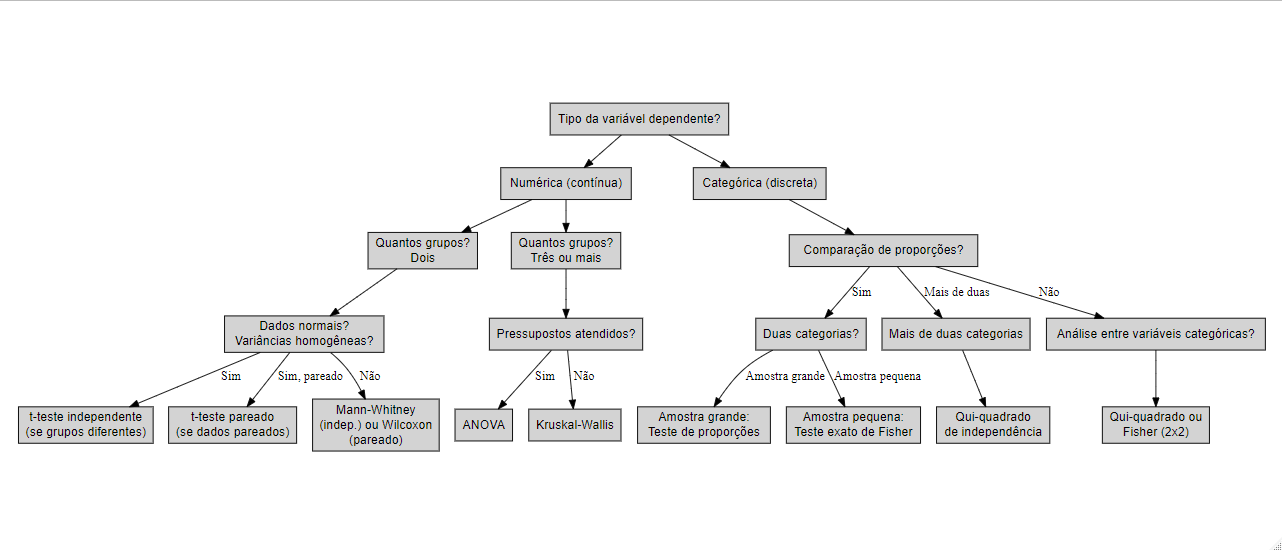
Para uma guia mais detalhado de que testes usar, veja a árvore de descisão:
Árvore de Descisão para Testes de Hipóteses
Lembre-se que pode usar testes para checar os pressupostos de outros testes.
Considerações finais
Antes de aplicar qualquer teste:
Verifique os pressupostos (ex: normalidade, homocedasticidade).
Visualize os dados (boxplots, histogramas).
Use o valor-p em conjunto com o contexto do problema.
Conclusão
Parabéns! Ao longo desta seção, você explorou os fundamentos e aplicações dos testes de hipótese, ferramentas essenciais para tomar decisões baseadas em dados. Esses testes nos ajudam a responder perguntas como:
“Existe uma diferença significativa entre dois grupos?”
“Será que esse padrão que estamos observando pode ter ocorrido por acaso?”
Mais do que seguir fórmulas, a ideia é desenvolver o raciocínio estatístico necessário para analisar e interpretar os dados com segurança.